

ファインチューニングとは?意味や転移学習・RAGとの違い・活用方法を解説
最終更新日:2025/12/08
 ファインチューニングとは?
ファインチューニングとは?
ファインチューニングは、AI開発の現場で重要性を増している技術です。すでに大量のデータで訓練されたモデルを、特定のタスクやデータセットに合わせて微調整することで、追加学習する手法です。
その結果、時間とリソースを大幅に節約しながら、AIモデルの性能を向上させられます。本記事では、ファインチューニングの基礎と実践方法について解説します。
ファインチューニングとは

ファインチューニングとは、既存の機械学習モデルを特定のタスクやデータセットに対して最適化するプロセスのことです。この手法は、モデルが元々訓練されたデータセットとは異なる新しいデータに対しても良好なパフォーマンスを発揮できるようにするために使用されます。
具体的には、モデルの一部または全体を再訓練し、新しいタスクに対する予測精度を高めることが目的です。
ファインチューニングを実施する意味
ファインチューニングを実施する目的は、モデルの汎用性を高め、特定の問題への解決能力を向上させることです。例えば、一般的な画像生成モデルに特定のイラストレーターの画風を学習させ、その画風を模倣した画像生成タスクを実行できます。
ファインチューニングにより、限られたデータセットでもモデルの性能を最大限に引き出せるようになります。
ファインチューニングの仕組み
ファインチューニングでは、まず基本となる大規模なデータセットで訓練されたモデルを用意します。次に、このモデルを新しい、特定のタスクに関連するデータセットで再訓練します。モデルの最終層だけを調整するか、場合によっては複数の層を調整するかなどして、新しいタスクに最適なパラメータを見つけます。
この調整によって、モデルは新しいデータに対する予測能力を高められます。
ChatGPTで使われている理由
ファインチューニングは、ChatGPTのような自然言語処理モデルにとって重要な手法です。ChatGPTは、大量のテキストデータに基づいて訓練されていますが、ファインチューニングによって特定のトピックやユーザーの要望に合わせて対応でき、応答能力を高められます。
自然言語処理モデルは、より関連性の高い情報をユーザーに提供できるようになり、満足度を向上させることが可能になります。
ファインチューニングと他の手法の違い
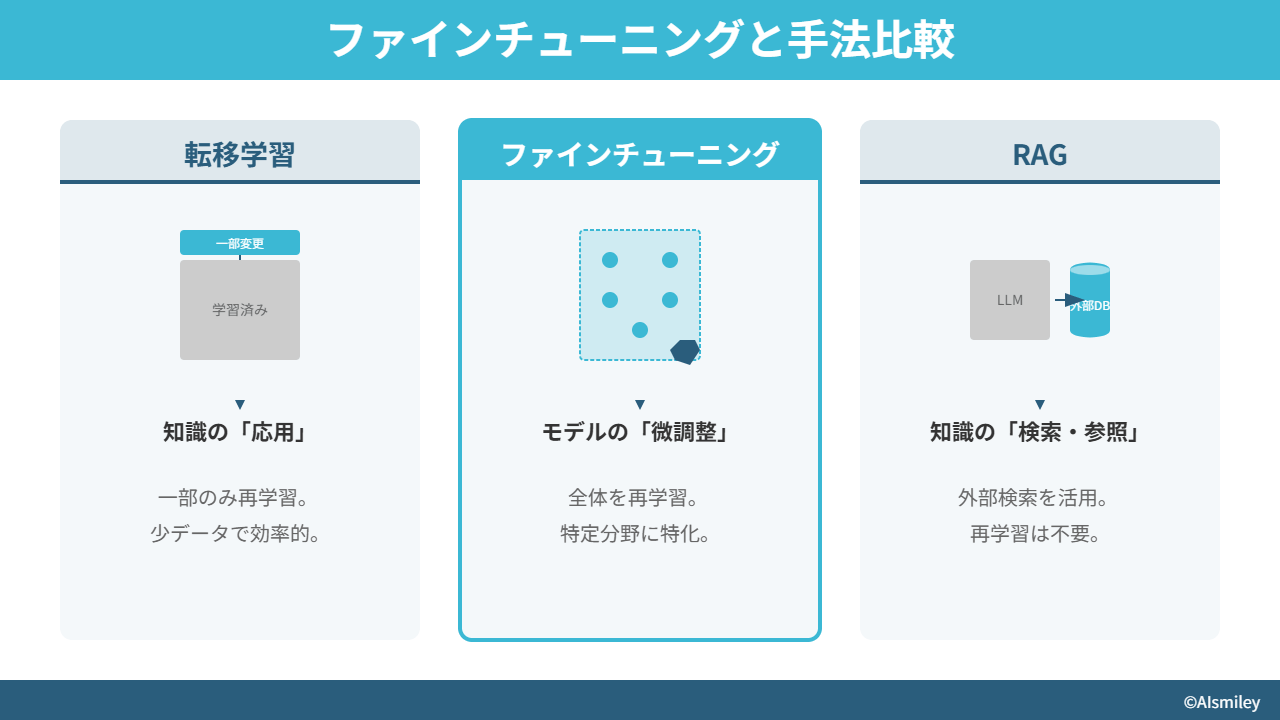
ファインチューニングは、転移学習やRAGといった機械学習手法としばしば比較されます。これらの手法もモデルの性能を向上させる目的で使用されますが、適応の仕方や目的において異なる点があります。ファインチューニングと他の手法とを比較して解説します。
転移学習とは
転移学習は、あるタスクで学習した知識を別の関連するタスクに適応する手法です。転移学習はファインチューニングの基盤となる概念であり、モデルが一度学習した特徴を、新しいタスクに再利用できます。たとえば、画像認識によって特徴を抽出するモデルを、医療用画像診断の学習に適応するということが可能です。
ファインチューニングは転移学習の一種と見なすことができます。ファインチューニングでは、既存モデルのパラメータを微調整して、新しいデータに適応させることに焦点を当てています。
RAGとは
RAG(Retrieval-Augmented Generation:検索拡張生成)は、情報検索を組み合わせた生成モデルで、特定の質問に対して最も関連性の高い情報を提供できます。RAGは、特定のデータベースや情報源から情報を取得し、その情報を基に応答を生成することで、特定の問いに対する精度の高い回答を提供します。
ファインチューニングとRAGの主な違いは、RAGが情報検索を直接的に統合する点にあります。一方、ファインチューニングはモデル自体の内部パラメータを調整することにより、既存の知識を新しいタスクやデータセットに適応します。
ファインチューニングのデータセットのやり方(作り方)

ファインチューニングのデータセットのやり方、作り方として以下の手順を紹介していきます。
- タスクを定義する
- データを収集する
- データの前処理を行う
- データセットを分割する
- データの拡張を行う
- データセットの品質を確認する
1.タスクを定義する
ファインチューニングを始める前に、解決しようとしている問題を明確に定義することが重要です。まずは、達成すべき具体的な目標を設定します。例えば、画像認識であればどのオブジェクトを識別するのか、自然言語処理であればどのような質問に答える能力を持たせたいのかを決定します。
明確なタスクの定義は、後続のデータ収集と前処理の方向性を決める際に重要です。
2.データを収集する
タスクが定義されたら、そのタスクを学習するための必要なデータを収集します。このデータは、モデルが解決しようとする問題に関連するものでなければなりません。データ収集は、公開データセットの利用、ウェブからのスクレイピング、手動でのラベル付けなど、さまざまな方法があります。
データ収集での重要な点は、収集されたデータがタスクにとって有意義であることと、多様性と量が十分であることです。
3.データの前処理を行う
収集したデータは、直接モデルに入力できる形式ではない可能性があります。そのため、データクレンジング(不要な情報の削除)、正規化(データを一定の範囲にスケーリング)、トークン化(テキストデータをモデルが処理しやすい単位に分割)などの前処理を行います。
データの前処理によって、データの品質が向上し、ファインチューニングの効率が高まります。
4.データセットを分割する
前処理を行ったデータセットを通常、訓練セット、検証セット、テストセットの3つに分割します。モデルが新しいデータに対してどれだけうまく一般化できるかを評価するためにデータセットの分割は重要です。適切なデータセットの分割比率は、タスクやデータの量によって異なりますが、一般的には訓練セットが最も大きな割合を占めます。
5.データの拡張を行う
データの量が不足している場合や、より多様なデータをモデルに学習させたい場合は、データの拡張を行うことが有効です。例えば、画像データの場合は回転、反転、色調の変更などを行い、テキストデータの場合は同義語の置き換えや文の再構成を行って拡張します。
データの拡張は、モデルがよりロバスト(頑丈、頑健)になり、実世界の変動に対して強くなるのをサポートします。しかし、データの拡張を行う際には、元のデータセットの意味を変えないよう注意が必要です。
6.データセットの品質を確認する
データセットの準備が完了したら、その品質を確認します。データのバランス(各クラスが適切に代表されているか)、ラベルの正確性(データに付与されたラベルが正しいか)、欠損値や異常値の処理といった確認ポイントがあります。
高品質なデータセットを用意することで、ファインチューニングプロセスの成功率が高まります。
ファインチューニングを実施するメリット

ファインチューニングは、特にデータが限られている場合や、開発リソースが制約されている状況で、AIモデルの運用を可能にする重要な手段です。実施するメリットとして以下の点があります。
- 十分な教師データがなくてもAI運用ができる
- 開発コストやリソースを削減できる
十分な教師データがなくてもAI運用ができる
ファインチューニングを利用すると、限られた量のデータでも再訓練することができます。新しいタスクや小規模なデータセットに対しても、高い精度での予測が可能となります。特にデータ収集が困難、またはコストがかかってしまう分野で非常に有効です。
開発コストやリソースを削減できる
ファインチューニングにより、既に大量のデータで訓練されたモデルを再利用することができるため、ゼロからモデルを開発する必要がありません。モデル開発にかかる時間とコストを大幅に削減することが可能であり、既存のモデルを最適化することで、必要とされる計算リソースも低減されます。
小規模なチームや限られた予算でも、高品質なAIソリューションの開発が可能になります。
ファインチューニングの活用事例
ファインチューニングは、AIのさまざまな分野で活用され効果を発揮しています。以下に活用事例を紹介します。
- 自然言語処理
- 画像処理
- 音声処理
- 自動運転
- レコメンデーションシステム
自然言語処理
自然言語処理(NLP)では、ファインチューニングはモデルを特定の言語タスクに最適化するために用いられます、例えば感情分析やテキスト要約といったタスクです。大規模言語モデル(LLM)は、一般的な言語理解には優れていますが、特定の用途や領域に合わせてファインチューニングすることで、性能をさらに向上させられます。
例えば、医療記録の分析や法律文書の要約など、専門的な知識が必要な領域で大きな効果を発揮します。
画像処理
画像処理分野では、ファインチューニングを通じて、特定の画像認識タスクを高精度で実現します。例えば顔認識や物体検出などにおいてです。既存の汎用的な画像認識モデルを特定のデータセットに対して再訓練することで、汎用モデルを特定のシナリオや要件に合わせて調整できます。
ファインチューニングによって、モデルは新しいタイプの画像に対しても、高い認識精度を発揮させることが可能です。
音声処理
音声処理においても、ファインチューニングは音声認識や音声生成タスクの精度向上に貢献しています。例えば、特定のアクセントや言語、特有のボーカルの特性に対応できるようになります。既存の音声モデルを特定のデータセットでファインチューニングし、ユーザーはより自然で正確な音声認識や音声生成を体験できるようになります。
自動運転
自動運転技術におけるファインチューニングの役割は、車両が複雑な道路環境を認識し、適切に反応する能力を高めることです。国ごとに交通ルールが異なったり、地域によって道路事情や気候が異なったりします。特定の交通状況や天候条件下での運転データを用いて、自動運転支援システムをファインチューニングすることで対応できるようになります。
グローバルモデルをそのまま使うだけでは、局所的な最適ができないため、システムはさまざまなシナリオに対してより効果的に対応するために、ファインチューニングを行うことが必要です。
レコメンデーションシステム
レコメンデーションシステムでファインチューニングを活用すれば、ユーザーの好みや行動パターンに合わせた個別に最適化された推薦を生成できます。大量のユーザーデータに基づいて訓練された一般的な推薦モデルを、特定のドメイン(領域)やニーズに合わせて微調整することで、推薦の精度と関連性を高められます。
ユーザーは自分の興味や好みにより密接に合致したコンテンツや商品を発見しやすくなります。
ファインチューニングを実施する際の注意点

ファインチューニングは多くのメリットをもたらしますが、実施する際には、以下のようにいくつかの注意点があります。
- 計算の負荷が大きい
- 設備投資が必要
- 教師データありの学習モデルに劣る可能性がある
計算の負荷が大きい
ファインチューニングは計算資源を大量に消費します。特に、大規模なモデルや複雑なデータセットを扱う場合、必要な計算量は膨大になり得ます。高性能なGPUやTPUなどの専用ハードウェアの利用、クラウドコンピューティングサービスの活用などが必要です。
計算資源の確保と適切な管理は、ファインチューニングプロジェクトの成功に不可欠です。
設備投資が必要
前述の通り、ファインチューニングは高い計算能力を要求します。そのため、必要なハードウェアやソフトウェアの購入、クラウドサービスの利用には、相応の投資が必要です。特にスタートアップや小規模な研究チームにとっては、このコストが大きな負担となることもあります。
計画的な投資と効率的な資源利用が、プロジェクトの成功を左右します。
教師データありの学習モデルに劣る可能性がある
ファインチューニングは効率的に高品質なモデルを構築できる方法ですが、元のデータセットや学習方法によっては、完全に新しいデータで学習させたモデルよりも性能が劣る場合があります。ファインチューニングする際には、目的とするタスクやデータセットの特性を十分に理解し、適切な前処理と調整を行うことが重要です。
また、期待する性能が得られない場合には、モデルのアーキテクチャの見直しや、教師データの質と量の改善が必要になることもあります。
まとめ
ファインチューニングは、AI分野における進歩をもたらします。メリットには十分な教師データがなくてもAI運用できる点や、開発リソースやコストを削減できる点です。
一方で注意する点もいくつか挙げられます。適切な計画と実施、資源の管理が重要です。これらの注意点を理解し、対策することで、ファインチューニングを最大限に活用し、AIに関するプロジェクトの成功につなげられます。
アイスマイリーでは「生成AI のサービス比較と企業一覧」を提供しています。最新のAIサービス動向を把握し、比較検討するために以下よりぜひご活用ください。
DXトレンドマガジン
メールマガジン登録
業務の課題解決に繋がる最新DX・情報をお届けいたします。
メールマガジンの配信をご希望の方は、下記フォームよりご登録ください。登録無料です。


AI・人工知能記事カテゴリ一覧
AI・人工知能サービス
- AIエージェント
- LLM
- AI研究開発
- ChatGPT
- 画像生成AI
- 生成AI
- RAG
- DX推進
- おすすめAI企業
- チャットボット
- ボイスボット
- 音声認識・翻訳・通訳
- 画像認識・画像解析
- 顔認証
- AI-OCR
- 外観検査
- 異常検知・予知保全
- 自然言語処理-NLP-
- 検索システム
- 感情認識・感情解析
- AIモデル作成
- 需要予測・ダイナミックプライシング
- AI人材育成・教育
- アノテーション
- AI学習データ作成
- エッジAI
- IoT
- JDLA
- G検定
- E資格
- PoC検証
- RPAツール
- Salesforce Einstein
- Watson(ワトソン)
- Web接客ツール
- サプライチェーン
- メタバース
- AR・VR・デジタルツイン
- MI
- スマートファクトリー
- データ活用・分析
- 機械学習
- ディープラーニング
- 強化学習
- テレワーク・リモートワーク
- マーケテイングオートメーション・MAツール
- マッチング
- レコメンド
- ロボット
- 予測
- 広告・クリエイティブ
- 営業支援・インサイドセールス
- 省人化
- 議事録自動作成
- 配送ルート最適化
- 非接触AI
業態業種別AI導入活用事例
今注目のカテゴリー
チャットボット

AI-OCR

フィジカルAI

生成AI
チャットボット
AI-OCR
フィジカルAI








FOLLOW US
SNSをフォローして、最新情報をチェックできます!

PKSHA InfinityのAI議事録作成ツール「YOMEL」…

NECとJR東日本、「みどりの窓口AI対応サービス」の実現に向け…

2026年上半期トレンドワードランキングをPR TIMESが公開…

OpenAI、グローバルパートナープログラム「OpenAI Pa…

Google Workspace Studioで実現する、AI時代の業務ルーティン──AIが裏で勝手に働き出す「イベント駆動型」の自動化

ポケモンカードAIエージェント開発コンテスト「ポケカABC」開催。松尾研・ポケモン・HEROZが共催

Preferred Networks、国産生成AI基盤モデル「PLaMo 3.0 Prime」を正式提供開始。

Anthropic、一般向けMythos級AIモデル「Claude Fable 5」、サイバー防衛向け「Claude Mythos 5」発表

パソナJOB HUBとEpicAI、「AI活用型BPO」共同事業化に向け協業開始。建設業界の業務整理とAI定着を推進

DCON2026優勝チームは「豊田工業高専」評価額は5億6000万円!
AI製品・ソリューションの掲載を
希望される企業様はこちら