

東大松尾研究室、日英対応の100億パラメータサイズの大規模言語モデル「Weblab-10B」を公開
最終更新日:2024/01/17
 松尾研 日英対応LLMを公開
松尾研 日英対応LLMを公開
東京大学松尾研究室は、100億パラメータサイズの大規模言語モデル「Weblab-10B」を開発し、2023年8月18日にモデルを公開しました。
このAIニュースのポイント
- 東京大学松尾研究室は、日英2か国語に対応のLLM「Weblab-10B」を事前学習と事後学習により開発
- 日本語だけでなく英語のデータセットも学習に用い、言語間の知識移転を行うことで日本語の精度向上が見られた
- 事後学習後のモデルは、公開済みの日本語大規模言語モデルで最高水準の精度
東京大学松尾研究室は、日英の2ヶ国語に対応した100億パラメータサイズの大規模言語モデル「Weblab-10B」を、事前学習と事後学習により開発し、非商用ライセンスでモデルを無料公開しました。

生成サンプル文
近年の大規模言語モデルは、インターネットから収集した大量のテキストデータを学習に用いますが、そのテキストデータの多くは英語などの一部の主要言語で構成されており、現状では日本語など、主要言語以外のテキストデータを大量に収集することに限界がありました。
松尾研究室が今回開発した「Weblab-10B」は、日本語だけでなく英語のデータセットも学習に用いることで、学習データ量を拡張し、言語間の知識転移を行うことで日本語の精度を高めています。
日英2ヶ国語対応の大規模言語モデル開発にあたり、事前学習には代表的な英語のデータセットThe Pileおよび日本語のデータセット Japanese-mC4を、事後学習には、Alpaca(英語)、Alpaca(日本語訳)、Flan 2021(英語)、Flan CoT(英語)、Flan Dialog(英語)の5つのデータセットを使用しています。事後学習の日本語データ比率が低いにも関わらず、日本語のベンチマークであるJGLUE評価値が事前学習時と比べて、66%から78%と大幅に改善し、この数値は国内の公開モデルとしては最高水準の精度を誇ります。
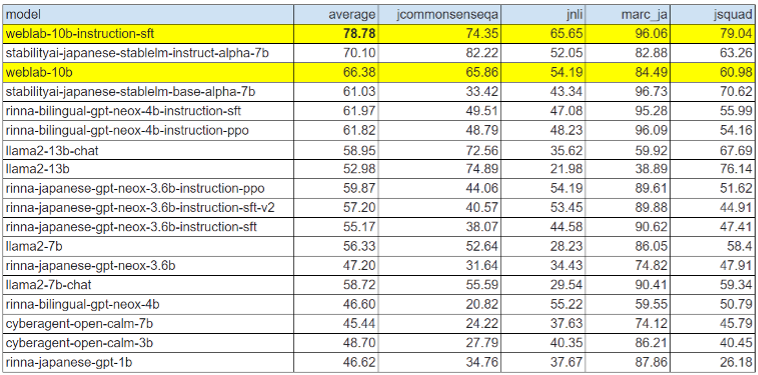
公開されている日本語対応モデルの比較表
松尾研究室は「今後も、Weblab-10Bのさらなる大規模化を進めるとともに、LLMの産業実装に向けた研究を推進していきます」とコメントしています。
出典:東京大学松尾研究室
DXトレンドマガジン
メールマガジン登録
業務の課題解決に繋がる最新DX・情報をお届けいたします。
メールマガジンの配信をご希望の方は、下記フォームよりご登録ください。登録無料です。


AI・人工知能記事カテゴリ一覧
AI・人工知能サービス
- AIエージェント
- LLM
- AI研究開発
- ChatGPT
- 画像生成AI
- 生成AI
- RAG
- DX推進
- おすすめAI企業
- チャットボット
- ボイスボット
- 音声認識・翻訳・通訳
- 画像認識・画像解析
- 顔認証
- AI-OCR
- 外観検査
- 異常検知・予知保全
- 自然言語処理-NLP-
- 検索システム
- 感情認識・感情解析
- AIモデル作成
- 需要予測・ダイナミックプライシング
- AI人材育成・教育
- アノテーション
- AI学習データ作成
- エッジAI
- IoT
- JDLA
- G検定
- E資格
- PoC検証
- RPAツール
- Salesforce Einstein
- Watson(ワトソン)
- Web接客ツール
- サプライチェーン
- メタバース
- AR・VR・デジタルツイン
- MI
- スマートファクトリー
- データ活用・分析
- 機械学習
- ディープラーニング
- 強化学習
- テレワーク・リモートワーク
- マーケテイングオートメーション・MAツール
- マッチング
- レコメンド
- ロボット
- 予測
- 広告・クリエイティブ
- 営業支援・インサイドセールス
- 省人化
- 議事録自動作成
- 配送ルート最適化
- 非接触AI
業態業種別AI導入活用事例
今注目のカテゴリー
ChatGPT連携サービス

チャットボット

AI-OCR

生成AI
ChatGPT連携サービス
チャットボット
AI-OCR










FOLLOW US
SNSをフォローして、最新情報をチェックできます!
清水建設、鉄筋の加工・組立作業に「フィジカルAI」導入。スイスM…

クラダシ「Claude」を全社展開。特有業務の自動化の推進および…

Sakana AI、マルチエージェント基盤「Sakana Fug…
デンソーテン、独自の埋め込みモデル学習技術により車載エッジでRA…

【CES 2026完全まとめ】AI実装がもたらす5つの最新トレンドと受賞例

カゴメなど5者、AI選果機の共同開発と実証の成果を発表。トマトの廃棄ロスを30%低減
TBSラジオ、AIで音声CMを生成する「デモCMジェネレーター」を公開。音声広告企画を支援

電通デジタル、OpenAIとdentsu Japanの戦略的連携に続き、ChatGPT広告のパイロット運用を開始

LINEヤフー、Agent iの機能拡大。画像生成機能やパーソナライズ機能を追加

Google Cloud、Nano Banana 2とNano Banana Proの一般提供を開始。動画の内容に合った画像を生成
AI製品・ソリューションの掲載を
希望される企業様はこちら