

生成AI

最終更新日:2026/02/20
 NVIDIA CUDAとは?
NVIDIA CUDAとは?
近年のAI技術や科学計算の急速な発展を支えているのが、NVIDIA CUDAテクノロジーです。この記事では、並列処理の基礎から実践的な活用方法まで、CUDAの全体像を分かりやすく解説します。
プログラミングやGPU計算に興味がある方、特にAI開発者やデータサイエンティスト、科学計算に携わる研究者の方々にとって、CUDAの理解は今や必須のスキルとなっています。
本記事を読むことで、以下のメリットが得られます。
初心者から専門家まで、CUDAの可能性を最大限に引き出すための知識を身につけましょう。

NVIDIA CUDAは、グラフィックス処理に特化したGPUの並列計算能力を、一般的な計算処理にも活用できるようにした革新的なプラットフォームです。
従来GPUは画像処理などに使われていましたが、CUDAの登場により科学計算やデータ解析など幅広い分野で利用できるようになりました。
並列処理の基本概念として重要なのは、CPUとGPUの役割分担です。
この特性を活かし、適切なタスク分配を行うことで処理効率が飛躍的に向上します。例えば、ディープラーニングの行列計算では、従来のCPU処理と比較して10〜100倍の高速化も可能になっています。
CUDAプログラミングでは、この並列処理の特性を理解し、データをどのように分割して処理するかが重要なポイントとなります。適切な並列化戦略を立てることで、科学シミュレーションや金融工学、医療画像解析など演算負荷の高い処理を劇的に加速できるのです。
| プロセッサ | 役割・得意分野 |
| CPU (Host) | 複雑な制御、分岐処理、プログラム全体の管理 |
| GPU (Device) | 単純な計算の大量並列処理、画像処理、行列演算 |
GPGPUとは「General-Purpose computing on Graphics Processing Units(GPUによる汎用計算)」の略称で、本来はグラフィック処理に特化していたGPUの並列計算能力を、一般的なデータ処理や科学技術計算に活用する技術概念です。
従来のGPUは3Dゲームや映像編集などの画像処理に使われていましたが、その高い並列処理能力が他の計算処理にも応用できることが認識されるようになりました。
GPGPUの最大の特徴は以下の点にあります。
NVIDIA CUDAはこのGPGPU技術を実現するための代表的なプラットフォームであり、科学計算、機械学習、暗号通貨マイニングなど様々な分野で活用されています。
CPUが数個〜数十個のコアで複雑な処理を行うのに対し、GPUは数千のコアで単純な計算を同時実行することで、適切な問題に対しては10倍以上の処理速度向上を実現できます。
現代のコンピューティングでは、CPUとGPUが明確な役割分担をしています。CPUはプログラム全体の制御や複雑な条件分岐、逐次処理を得意とする「指揮者」の役割を担います。
一方、GPUは単純だが膨大な数の計算を同時に処理する「オーケストラ」として機能します。
典型的なCUDAプログラムの処理フローは以下の通りです。
この役割分担により、例えば画像処理では、CPUがファイル読み込みやユーザーインターフェース処理を担当し、ピクセル単位の並列計算をGPUに任せることで、システム全体の処理効率が飛躍的に向上します。
最適な設計では、GPUの計算能力を最大限活用しつつ、CPUとGPUの間のデータ転送オーバーヘッドを最小化することが重要です。
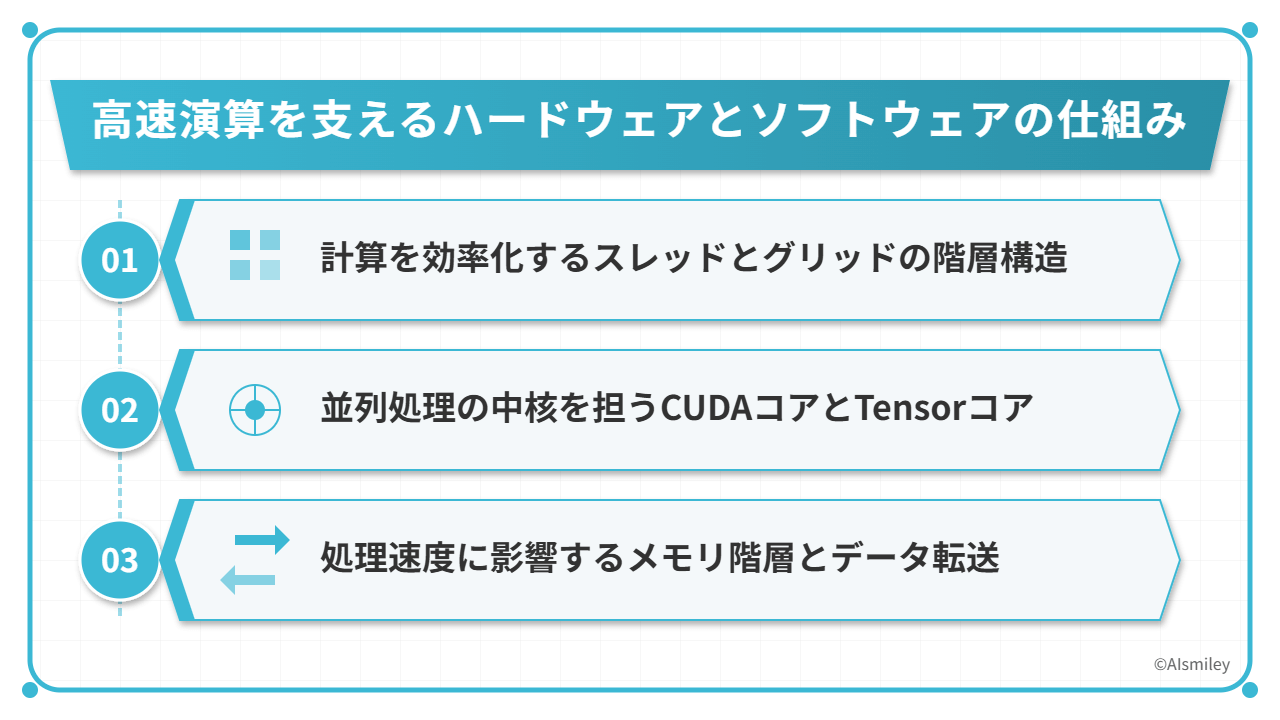
NVIDIAのCUDA技術が実現する高速並列演算の秘密は、ハードウェアとソフトウェアが緻密に連携する独自のアーキテクチャにあります。
この仕組みを理解することで、なぜGPUが特定の計算タスクでCPUを圧倒的に上回るパフォーマンスを発揮できるのかが見えてきます。
CUDA技術の中核となるのは、以下の3つの要素です。
これらの要素が連携することで、GPUは数千のコアを同時に稼働させ、大量のデータを並列処理できるのです。
特にメモリ階層の適切な活用は、データ転送のボトルネックを解消する鍵となります。ソフトウェア側では、これらのハードウェア特性を最大限に引き出すための専用APIとプログラミングモデルが提供されています。
CUDAの並列計算処理を支える基盤となるのが、スレッドとグリッドの階層構造です。
この構造では、計算の最小単位である「スレッド」が複数集まって「ブロック」を形成し、さらにそれらのブロックが集まって「グリッド」を構成します。
この階層化によって、GPUは以下のような効率的な処理が可能になります。
特に大規模なデータセット処理において、この構造が威力を発揮します。例えば画像処理では、1つのピクセルをスレッドに割り当て、画像の特定領域をブロックとして処理することで、4K解像度の画像でも比較的短時間で処理できます。
開発者はこの階層構造を活用することで、ハードウェアの詳細を意識せずとも効率的な並列アルゴリズムを実装できます。スレッド間の同期やメモリ共有も、この構造を基盤に最適化されています。
NVIDIAのGPUアーキテクチャの心臓部とも言えるのが、CUDAコアとTensorコアです。CUDAコアは浮動小数点演算や整数演算を担当する基本的な演算ユニットで、数千個単位で搭載されています。
これらが同時並列で動作することで、CPUでは到底実現できない計算処理能力を発揮します。
特に注目すべきは、最新世代のGPUに搭載されるTensorコアです。
これは行列演算を専門に処理するための特殊なコアで、以下の特徴があります。
CUDAコアが汎用的な計算処理を担当する一方、Tensorコアは特に機械学習のワークロードに最適化されています。
例えば画像認識では、従来のCUDAコアだけの処理と比較して、Tensorコアを活用することで3〜10倍の性能向上が見られるケースもあります。
これらのコアは気象シミュレーション、創薬研究、自動運転の開発など、高度な並列処理を必要とする多様な分野で革命的な計算能力をもたらしています。GPUの世代が進むごとにこれらのコア数と性能は向上し続け、かつては不可能だった規模の計算が現実のものとなっています。
GPUの処理速度を最大限に引き出すには、メモリ階層の理解が不可欠です。GPU内には複数のメモリ層が存在し、それぞれ特性が異なります。
グローバルメモリは容量が大きい反面、アクセス速度が比較的遅く、シェアードメモリはブロック内で共有される高速なメモリ領域です。さらに、レジスタは各スレッド専用の超高速メモリとして機能します。
これらを適材適所で活用することがパフォーマンスの鍵となります。
特に注意すべきは、CPUとGPU間のデータ転送です。この転送はPCIeバスやNVLink-C2Cを介して行われるため、以下のようなボトルネックが生じやすくなります。
これらを回避するためには、以下が必要です。
また、メモリアクセスパターンの最適化も重要です。協調アクセス(coalesced access)を実装することで、同一ワープ内のスレッドが連続したメモリ領域にアクセスし、スループットを大幅に向上させることができます。
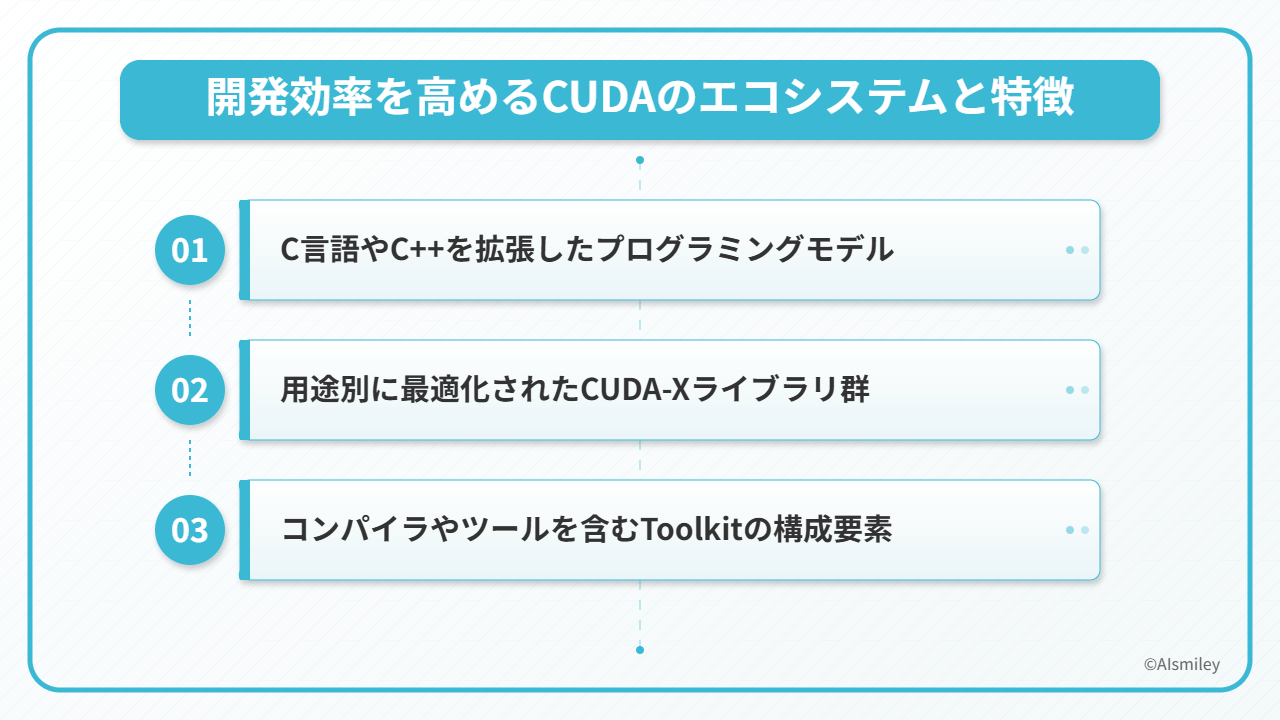
CUDAが多くの開発者から高い支持を得ている理由は、そのエコシステムの充実度にあります。
特に注目すべきは、既存のC/C++の知識を活かせるプログラミングモデルを採用していることで、GPUプログラミングの学習曲線を大幅に緩やかにしています。
CUDAエコシステムは主に3つの柱で構成されています。
これらの要素が有機的に連携することで、開発者はハードウェアの詳細を深く理解せずとも、GPUの並列処理能力を最大限に活用したアプリケーション開発が可能になります。
特に近年は、AIや科学計算の需要増加に伴い、エコシステムの重要性がさらに高まっています。
CUDAは、C言語やC++を基盤として拡張された独自のプログラミングモデルを提供しています。多くのプログラマーが既に習得しているこれらの言語をベースにしているため、GPUプログラミングへの移行が比較的スムーズに行えます。
特徴的なのは、「__global__」や「__device__」などの簡潔なキーワードを追加するだけで、GPU上で実行される関数(カーネル)を定義できる点です。
これにより、従来のCPUプログラミングの知識を活かしながら、並列処理の恩恵を受けることができます。
例えば、以下のような簡単な構文でGPU処理を実装できます。
また、CUDAは高級言語との連携も強化されており、PyCUDAやNumba、TensorFlowなどのフレームワークを通じて、Python環境からも容易にGPUの計算能力を活用できます。
これにより、機械学習や科学計算の分野でも、専門的なGPU知識がなくても高速化の恩恵を受けられるようになっています。
NVIDIAは開発者の生産性を高めるため、CUDA-Xと呼ばれる専門分野別に最適化されたライブラリ群を提供しています。
これらのライブラリは、低レベルのGPUプログラミングの複雑さを抽象化し、特定の用途に特化した高性能な機能を実現します。
例えば、ディープラーニングを加速する「cuDNN」は、畳み込みやプーリングなどのニューラルネットワーク演算を大幅に高速化し、AIフレームワークの基盤となっています。行列計算に特化した「cuBLAS」は科学計算や機械学習の線形代数演算を効率化し、画像処理向けの「NPP」は複雑なフィルタリングやトランスフォーメーションを簡単に実装できます。
これらのライブラリを活用することで、開発者は以下のメリットを得られます。
CUDA-Xライブラリは、科学シミュレーション、暗号通貨マイニング、ビデオエンコーディングなど、多様な分野での開発を加速し、GPUの能力を最大限に引き出す強力なツールセットとなっています。
NVIDIA CUDA Toolkitは、GPU向けアプリケーション開発に必要なツール群を包括的に提供する開発環境です。
その中核となるのがNVCC(NVIDIA CUDA Compiler)で、CUDA Cコードを解析してGPU実行可能なコードへと変換します。このToolkitには以下のような重要な構成要素が含まれています。
開発者はこれらのツールを活用することで、コードの記述からデバッグ、最適化まで一貫した環境で作業できます。Toolkitは定期的にアップデートされ、最新のGPUアーキテクチャやCUDA機能に対応しています。
特筆すべきは、Nsightシリーズのような高度な開発支援ツールが含まれており、Visual StudioやEclipseなどの一般的なIDEとの連携も可能な点です。
これにより、GPUプログラミングの学習曲線が緩やかになり、より多くの開発者がGPUの計算能力を活用できるようになっています。
NVIDIA CUDA Toolkitを活用した開発を始めるには、適切な環境構築が不可欠です。まずは全体の流れを把握しましょう。
環境構築は大きく分けて3つのステップで進めていきます。
特にGPUのCompute Capability(計算能力)を事前に確認することが重要です。これによって利用できるCUDAのバージョンが決まるためです。NVIDIAの公式サイトでは、GPUモデルごとの対応状況が詳細に記載されています。
インストール作業はOS環境によって手順が異なります。Windowsではインストーラーを使用する方法が一般的ですが、Linuxではパッケージマネージャーやrunファイルを使用します。
最新版が必ずしも最適とは限らないため、開発するアプリケーションやフレームワークとの互換性も確認しておきましょう。
環境変数の設定も忘れてはなりません。特にPATHへの追加は必須です。インストール完了後は「nvcc -V」コマンドで正しくToolkitが認識されているか確認できます。初回ビルド時のエラーは環境変数の設定ミスが多いので、トラブル発生時はまずここを見直しましょう。
CUDA開発を始める前に、お使いのGPUが持つ「Compute Capability」を確認することが重要です。
この値はGPUの世代や計算能力を示す指標であり、インストールすべきCUDA Toolkitのバージョンを決定する鍵となります。
Compute Capabilityの確認方法はいくつかあります。
例えば、GeForce RTX 3080はCompute Capability 8.6を持ち、CUDA 11.0以降をサポートしています。
一方、古いGTX 980などはCompute Capability 5.2で、最新のCUDAバージョンでは完全にサポートされていない可能性があります。
適切なバージョンを選ばないと、以下の問題が発生する恐れがあります。
特に最新のAI開発やディープラーニングフレームワークを使用する場合は、必要最小限のCompute Capabilityが指定されていることがあるため、事前の確認が非常に重要です。
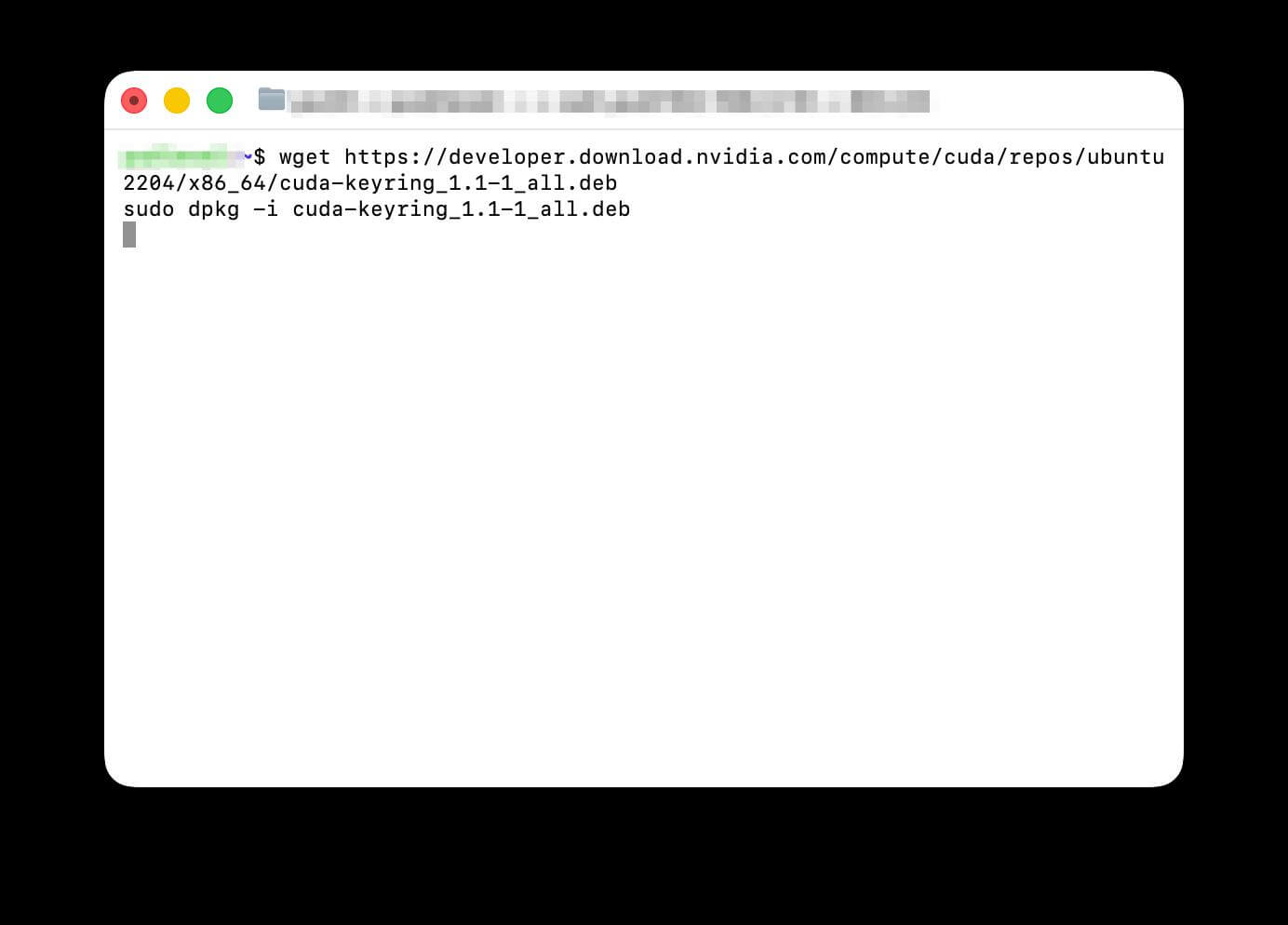
NVIDIA CUDA Toolkitのインストールは、OS環境によって手順が大きく異なります。Windows環境では、NVIDIAの公式サイトから専用インストーラーをダウンロードし、ウィザードに従って進めるだけで比較的簡単に導入できます。
一方、Linux環境では以下の手順で進めることが一般的です。
sudo apt install nvidia-driver-550
sudo rebootwget https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2204/x86_64/cuda-keyring_1.1-1_all.deb
sudo dpkg -i cuda-keyring_1.1-1_all.deb
sudo apt update
sudo apt install cuda-toolkit
どのOSでも、インストール後は環境変数の設定が必要です。特にLinuxでは`.bashrc`や`.profile`にPATHを追加することで、コマンドラインからCUDAツールにアクセスできるようになります。
最新バージョンのドライバとToolkitの組み合わせについては、NVIDIA公式のCompatibility Matrixを参照することで、互換性の問題を回避できます。特に本番環境では、安定版の使用が推奨されています。
CUDA Toolkit のインストール後は、環境変数の適切な設定が必須です。特に PATH、LD_LIBRARY_PATH(Linux)、CUDA_HOME などの変数を正しく構成しないと、コマンドが認識されない事態に陥ります。
環境変数の設定が完了したら、以下のコマンドで動作確認を行いましょう。
ビルドエラーが発生した場合、主な原因は次の通りです。
エラーメッセージを注意深く読むことが解決の第一歩です。特に「file not found」はパス設定、「unsupported GPU」はバージョン不一致を示唆しています。公式ドキュメントやNVIDIAフォーラムも問題解決の強力な味方となるでしょう。
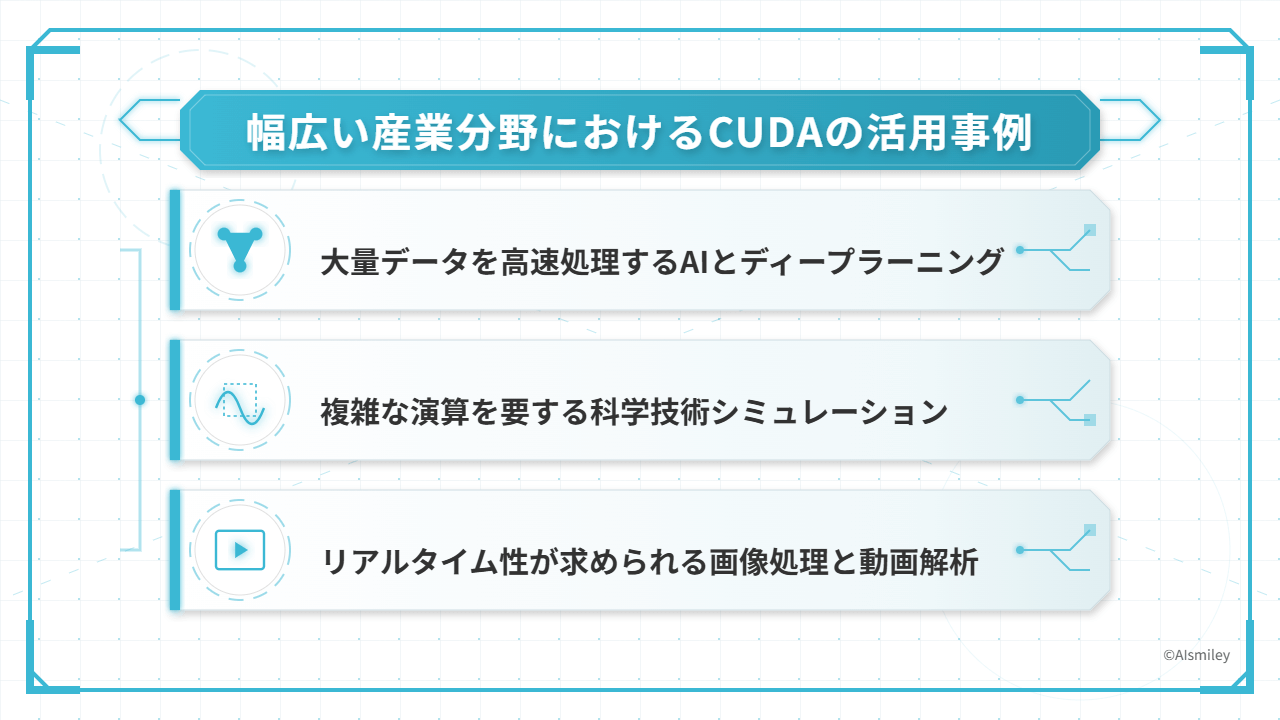
CUDAの並列処理技術は、今や私たちの生活や産業を支える縁の下の力持ちとなっています。特に計算負荷の高い分野では、従来のCPU処理では何日もかかっていた作業が、GPU並列計算によって数時間、時には数分に短縮されるケースも珍しくありません。
この革命的な技術革新は、様々な産業分野に変革をもたらしています。
例えば、
これらはほんの一例に過ぎません。CUDAの真価は、その柔軟性と拡張性にあります。研究者からエンジニア、クリエイターまで、様々な専門家がCUDAを活用して従来の限界を打ち破っています。
次のセクションでは、特に注目すべき3つの応用分野について詳しく見ていきましょう。
| 分野 | 活用事例・メリット |
| AI・ディープラーニング | 大規模言語モデル(LLM)の学習高速化、画像生成AI |
| 科学シミュレーション | 気象予測、流体解析、分子動力学の計算時間短縮 |
| 画像・動画処理 | リアルタイムレンダリング、物体検知、エンコード |
現代のAI開発において、NVIDIA CUDAは大量データの高速処理に不可欠な基盤技術となっています。特にディープラーニングモデルの学習では、数百万から数十億のパラメータを処理する必要があり、GPUの並列計算能力がなければ実用的な時間内での処理は困難です。
TensorFlowやPyTorchといった主要なディープラーニングフレームワークは、CUDAを標準でサポートしており、研究者や開発者は複雑なGPU最適化を意識せずに高速な計算環境を利用できます。これにより、以下の恩恵が得られています。
特に近年注目を集める生成AIやLLM(大規模言語モデル)の開発においては、CUDAによる並列処理がなければ、巨大モデルの学習は難しいケースが多くありました。企業の研究開発部門では、複数のGPUを連携させたマルチGPU環境を構築し、さらなる処理の高速化を実現しています。
科学技術シミュレーションの世界では、CUDAの並列処理能力が革命的な進化をもたらしています。気象予測システムでは、数百万のグリッドポイントにおける大気の動きを同時計算し、従来のCPUベースのシステムと比較して予報時間を大きく短縮しています。
流体力学の分野では、航空機や自動車の設計において、複雑な乱流シミュレーションをリアルタイムに近い速度で実行可能になりました。例えば、
分子動力学シミュレーションでは、数百万から数十億の原子間相互作用を追跡し、新薬開発や材料設計の過程を大幅に短縮しています。特に新型コロナウイルス対策の薬剤開発では、CUDAを活用したシミュレーションが研究を加速させました。
構造解析の分野では、複雑な建築物や橋梁の耐震性能を高精度に予測し、設計の安全性向上に貢献しています。金融工学においても、リスク分析やオプション価格計算などの計算負荷の高い処理を瞬時に実行できるようになりました。
これらのシミュレーションは、従来のCPUでは数週間かかっていた処理が、CUDA対応GPUでは数時間から数分に短縮されています。精度を犠牲にすることなく計算速度を劇的に向上させることで、科学技術イノベーションの加速に大きく貢献しているのです。
画像処理と動画解析の分野では、CUDAの並列処理能力が真価を発揮しています。監視カメラの映像からリアルタイムで不審者を検知するセキュリティシステムや、自動運転車の周囲環境認識など、遅延が許されない場面で活躍しています。
特に注目すべき活用例として、
Adobe PremiereやDaVinci Resolveなどの映像編集ソフトでは、GPUアクセラレーションによってエフェクト適用やカラーグレーディングが瞬時に行えるようになりました。以前はレンダリングに長い時間がかかっていた処理が、CUDAの活用により短い時間で完了します。
また、SNSプラットフォームでは日々多くの画像や動画がアップロードされ、不適切コンテンツの自動検出にCUDAベースの画像認識が不可欠となっています。このようなリアルタイム処理能力は、クリエイティブワークフローの効率化だけでなく、社会インフラの安全性向上にも大きく貢献しているのです。

NVIDIAのGPUアーキテクチャは急速な進化を遂げており、CUDAエコシステムもそれに合わせて拡張し続けています。次世代技術の中でも特に注目すべきは、生成AIの時代に対応した革新的なアーキテクチャの登場です。
最新のBlackwellアーキテクチャは、生成AIモデルの処理に特化した設計を採用し、前世代と比較して驚異的な性能向上を実現しました。特に以下の3つの革新が重要です。
一方、Grace Hopper Superchipは、CPUとGPUを統合したアプローチにより、従来のボトルネックを解消しています。このアーキテクチャでは、
これらの技術革新により、AIトレーニングと推論の両方で大幅な高速化が期待できます。次世代アーキテクチャは単なる性能向上だけでなく、新たな計算パラダイムを創出し、これまで実現不可能だった応用分野を切り開くでしょう。
NVIDIAが2024年に発表したBlackwellアーキテクチャは、生成AIとLLM(大規模言語モデル)処理のために特別に設計された革新的なGPUプラットフォームです。従来のHopperアーキテクチャと比較して、AIワークロードの処理速度を大きく向上させる能力を持っています。
この飛躍的な性能向上を支える技術的な特徴として、以下が挙げられます。
Blackwellアーキテクチャは特に推論処理において圧倒的な効率性を発揮し、ChatGPTのような大規模AIモデルの応答時間を劇的に短縮します。また、電力効率も大幅に改善されており、同じ計算量に対して推論の運用コストとエネルギーを削減できます。
CUDA Toolkitも今後このアーキテクチャに最適化されたバージョンがリリースされ、開発者はBlackwellの革新的な機能をフル活用できるようになるでしょう。これにより、より複雑なAIモデルの開発や、リアルタイム生成AIアプリケーションの実現が可能になります。
NVIDIAの「Grace Hopper Superchip」は、CPUとGPUの間のデータ転送という長年の課題を解決する画期的な技術です。従来のシステムでは、CPUとGPU間のPCIeバスによる通信がボトルネックとなっていましたが、このスーパーチップではNVLink-C2Cという超高速インターコネクトにより、最大900GB/秒という驚異的な帯域幅を実現しています。
このアーキテクチャの最大の特徴は、統合メモリ空間の実現です。これにより、
特に大規模AIモデルや科学計算において、このメモリ効率化は処理時間を劇的に短縮します。さらに、ソフトウェア面でもCUDA統合メモリの拡張により、プログラミングモデルが簡素化されています。開発者はハードウェアの詳細を気にせず、より直感的にGPUプログラミングに取り組めるようになりました。
今後は、さらなるメモリ階層の最適化やスマートキャッシング技術の導入により、AIワークロードに特化した進化が期待されています。Grace Hopperは単なる性能向上だけでなく、GPUコンピューティングの使いやすさを根本から変える技術なのです。
NVIDIA CUDAは、GPUの並列処理能力を最大限に活用するための革新的なプラットフォームです。本記事では、GPGPUの基本概念から、CUDAの階層構造、メモリ管理、そして豊富なライブラリ群まで幅広く解説しました。
CUDAを活用することで、AIや科学計算、画像処理など多様な分野で処理速度を飛躍的に向上させることが可能になります。特に以下の知識は、最新のBlackwellアーキテクチャやGrace Hopperなど次世代技術への理解にも繋がります。
CUDAの環境構築から実践的な活用まで、本記事の内容を参考に、ぜひGPUの並列処理能力を皆さんのプロジェクトに取り入れてみてください。計算処理の世界が一変するような体験が待っていることでしょう。
アイスマイリーでは、生成AI のサービス比較と企業一覧を無料配布しています。課題や目的に応じたサービスを比較検討できますので、ぜひこの機会にお問い合わせください。
業務の課題解決に繋がる最新DX・情報をお届けいたします。
メールマガジンの配信をご希望の方は、下記フォームよりご登録ください。登録無料です。

















FOLLOW US
SNSをフォローして、最新情報をチェックできます!








AI製品・ソリューションの掲載を
希望される企業様はこちら