

生成AI

最終更新日:2026/04/17
 AI inside 全二重型音声対話モデル開発
AI inside 全二重型音声対話モデル開発
AI insideは、人との対話と業務の実行を同時に処理する全二重型音声対話モデルを開発しました。発話中から処理を進めることで、リアルタイムな会話応答を実現します。
このニュースのポイント
AI inside 株式会社は、人との対話と業務の実行を同時に処理する全二重(Full-Duplex)型音声対話モデルを開発しました。
本研究開発は、経済産業省と国立研究開発法人新エネルギー・産業技術総合開発機構(NEDO)が実施する日本国内における生成AIの開発力強化を目的としたプロジェクト「GENIAC」に採択された研究テーマ「一貫性のある日本語Full-Duplex-SpeechマルチモーダルLLMの研究開発」の成果に基づくものです。
本モデルは、人の発話の途中から意図を捉え、応答生成や業務処理を即時に開始します。従来の音声AIは発話が完了してから処理を開始していましたが、発話中から処理を進めることで、リアルタイムな会話応答を実現します。
本研究では、日本語理解などの基礎能力を活かし、必要な部分のみ追加学習する手法を採用しました。モデル全体を作り直さず性能を向上させることで、既存の業務環境や用途に迅速に適応できる設計です。
この拡張性により、エッジコンピュータ「AI inside Cube」上での展開や既存プロダクトへの組み込みにも適しています。
雑談に対しては、会話の盛り上がりに応じて、発話内容を即時に変化させながら応答します。
仕事の相談をすると、確認応答に加え、笑い声などの非言語表現もリアルタイムに生成します。
旅行の相談をすると、相槌のタイミングと強度を自然に制御し、落ち着いた対話を維持します。
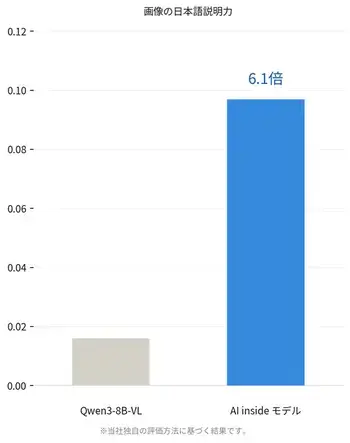
また、画像・音声・テキストを1つのモデルで統合的に処理する仕組みを実現しました。画像内容を日本語で説明する評価では、Qwen3-8B-VLとの比較において約6.1倍の説明精度を確認しています。
帳票・書類などの画像情報を認識し、音声指示と組み合わせて業務を実行する画像理解能力が、業務完遂AIの目として機能します。
自社AIエージェント基盤を用いた実証では、音声指示と帳票情報を組み合わせた業務プロセスの自律実行を検証しました。結果、特定条件下において従来の手作業と比べて完了時間の96%短縮を確認し、AIがプロセス全体を自律完遂して、人の介入を最小限に抑えた業務実行が可能であることを実証しました。
本研究で開発したモデルは今後、商用バージョンへのアップデートを行い、音声会話モデルや各種サービスへの展開を予定しています。
AI insideは、本研究の成果を基盤にマルチモーダル生成AIの研究開発と社会実装を推進し、AIを単なるツールではなく人と共に考え判断を支える存在へ進化させ、幅広い領域での活用を目指すとしています。
業務の課題解決に繋がる最新DX・情報をお届けいたします。
メールマガジンの配信をご希望の方は、下記フォームよりご登録ください。登録無料です。













FOLLOW US
SNSをフォローして、最新情報をチェックできます!









AI製品・ソリューションの掲載を
希望される企業様はこちら