

RAG(検索拡張生成)とは?仕組みや活用例、メリットを解説
最終更新日:2025/11/25
 RAG(検索拡張生成)とは?
RAG(検索拡張生成)とは?
ChatGPTをはじめとする大規模言語モデル(LLM)が浸透している現在、企業利用においては社内データなどを学習した特化型LLMシステムが求められるケースも増えています。LLMの外部データを参照し、情報を取得する手法の1つが「RAG(検索拡張生成)」と呼ばれる技術です。
本記事では、RAGの仕組みやLLMとの関係性、活用するメリットや実装方法などについて解説します。RAGの活用例なども紹介しますので、RAGについて理解を深め自社における効果的な生成AIの導入、運用を実現するためにぜひお役立てください。
一刻も早くRAG関連のサービスを比較検討したいという方はこちらから確認できます。
RAG(検索拡張生成)とは?
RAG(Retrieval-Augmented Generation:検索拡張生成)とは、検索エンジンのように外部データベースから情報を取得(Retrieval)し、それをもとに生成AIが自然な文章を出力(Generation)するという、検索と生成を組み合わせた自然言語処理(NLP)の手法です。
このアプローチでは、ユーザーの質問やプロンプトに対して、まず関連する外部ドキュメントや知識ベースを検索し、それらの情報を活用して、より正確で文脈に即した回答を生成します。これにより、生成モデル単体では難しい最新情報の反映や正確性の向上が可能になります。
さらにRAGは、単なる検索結果の要約にとどまらず、取得した情報を統合・整理し、文脈を考慮した自然で人間らしい言語表現による応答を実現します。
RAGシステムの仕組み
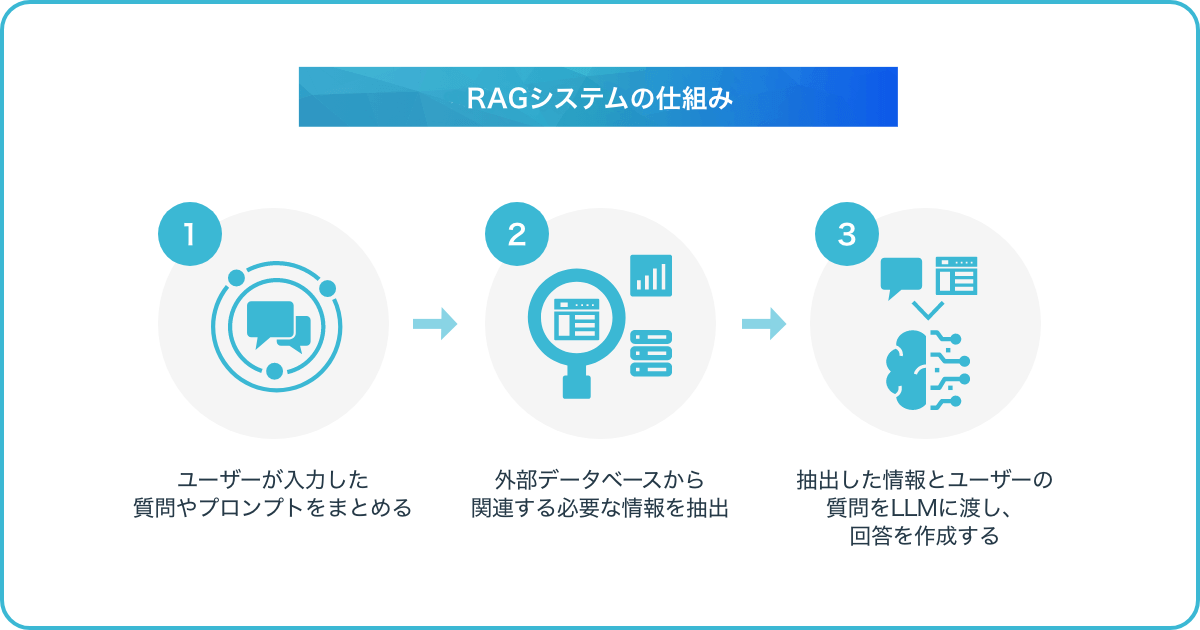
RAGは大きく分けて二つのフェーズで成り立っています。まず、AIが外部情報にアクセスし、最新の情報や文脈に即した情報を取得する検索フェーズ。
そして、その情報を利用して大規模言語モデル(LLM)が回答文を作成する拡張生成フェーズがあります。指定した外部情報から検索させるため正確性の向上が期待でき、ある分野に特化した専門性が高いデータを組み込んで回答させることもできます。
検索フェーズ
検索フェーズではユーザーがチャットなどでプロンプト(質問・指示)を入力し、AIが外部情報を検索してデータを取得します。このとき検索アルゴリズム(検索方法)によってRAGの性能が変わってきます。LLMに正しい情報を参照させることで回答の精度が変わるためです。RAGを構築する際の検索アルゴリズム(検索方法)は下記のようなものがあります。
- キーワード検索:文字列が一致したりパターンのマッチングで検索する方法
- ベクトル検索:単語や文章をベクトル化(数値化)し類似度を計算して検索する方法
- ハイブリッド検索:「キーワード検索」と「ベクトル検索」を組み合わせた方法
- セマンティック検索:キーワードの意味や意図を考慮して検索する方法
- ハイブリッド検索+セマンティック検索:ハイブリッド検索で得た結果をさらにセマンティック検索をし精度をたかめる方法
高性能なRAGを構築するためには検索方法が非常に重要になってきます。ただし、検索性能が高いほど計算コストがかかり応答が遅くなることや費用がかさんでしまうといったことが起こりえます。
生成フェーズ
検索フェーズで得られた結果とユーザーが入力したプロンプト(質問・指示)をセットでLLM(大規模言語モデル)に渡します。LLMはこれらの情報を文脈に応じて適切に解釈・統合し、単なるキーワードの羅列ではなく意味的な整合性を保った形で自然な回答文を生成します。
検索で得た情報は単なる補助材料として使われるのではなく、LLMの内部的な推論と組み合わせることで、より信頼性が高く、ユーザーの意図に沿った応答を実現します。ユーザー、LLM、データベースを連携するために、「LangChain」や「LlamaIndex」などのオープンソースのAI開発フレームワークが広く使用されています。
なぜRAGが必要なのか?
RAGは、LLM(大規模言語モデル)をはじめとする生成AIの短所を抑え、より有益な活用をするためのアーキテクチャや拡張手法と言えます。ここでは、RAGとLLMの関係性と解決できること、解決が難しい課題について解説します。
LLMの基礎知識などについて、詳しくはこちらの記事もご覧ください。
参考:大規模言語モデル(LLM)とは?仕組み・種類・活用サービス・課題をわかりやすく解説
RAGとLLMの関係性
RAGは、LLM(例:GPT、Claude、LlaMAなど)の文章生成能力を活かしつつ、その弱点である「知識の固定性」や「事実性の欠如」を補うために考案されたアーキテクチャです。LLM(大規模言語モデル)はRAGにおける出力の中核を担う存在で、検索で得た精度の高い情報をもとに人間らしい言語出力をする役割を果たします。
LLM(生成AI)の課題
LLMの課題には以下の点が挙げられます。
最新情報を扱えない
生成AIの学習データは、特定の時点で収集された情報です。そのため、学習後に発生した出来事や最新データは扱えない問題があります。
ハルシネーション
ハルシネーションとは、生成AIが学習データにない質問に対しても、それらしく見えてしまう文章を創作し回答してしまう問題です。
専門的な情報に弱い
生成AIは汎用的な知識には強いものの、特定業界や専門性の高い情報には弱い傾向があります。
回答根拠を示せない
生成AIは、どの情報源をもとに回答を生成したか明示できない場合があります。そのため信頼性や再現性の検証をしにくい課題があります。
RAGによる課題解決
生成AIにおいての課題をRAGが解決できる場合があります。RAGにより、最新で信頼性のある情報にアクセスできることに加えて、LLMが抱える課題を解消できるという効果が期待できます。現在のLLMでは、誤った回答をあたかも正しいかのように答える「ハルシネーション」や、「敵対的プロンプト」などのリスクが懸念されています。
LLMは質問に正確に答えることもあれば、学習データからいい加減な情報を吐き出すケースも報告されています。統計的な背景から、単語と単語の関係性を組み合わせるような形で文章を作成できても、意味まではわかっていないからです。
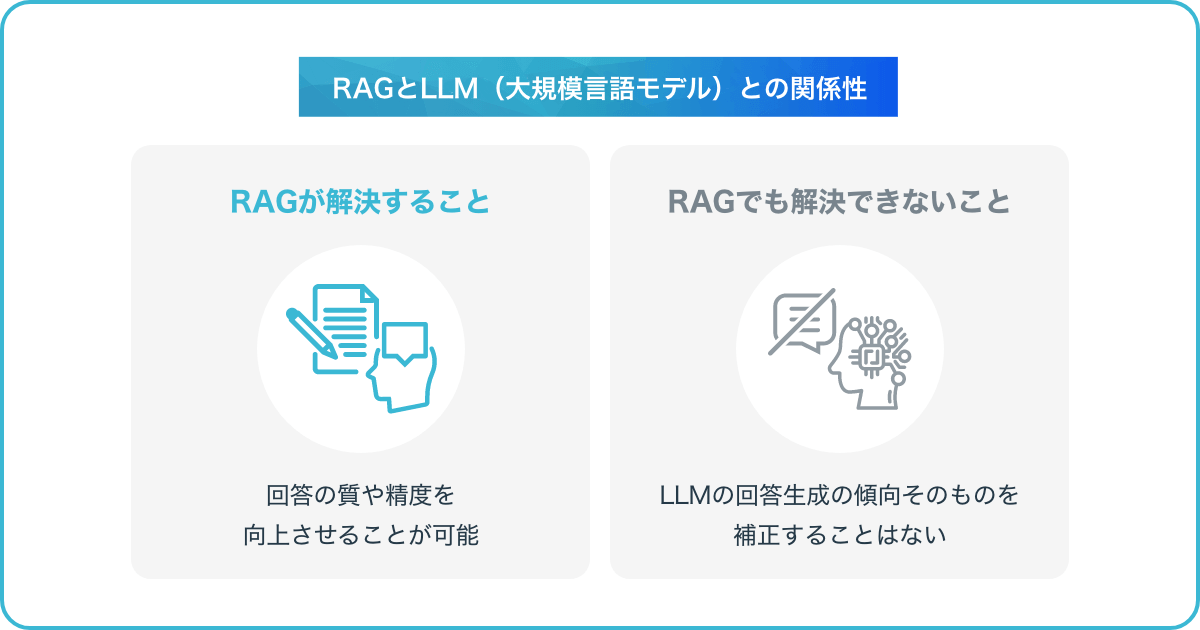
RAGを実装することで、LLMが持つ知識を補うための外部ソースへと誘導し、回答の質や精度を向上させることが可能です。また、最新情報やデータソースへのアクセスが実現することで、回答が正確かどうかをチェックしやすくなり、結果的に信頼性の保証にもつながります。
RAGでも解決できないこと
RAGはLLMの欠点を補完する役割を果たしますが、LLM自体に影響を与えることはありません。RAGでは、LLMの外に外部情報を検索する仕組みを持たせるため、LLMそのものの性質や動作ロジックを変えることはできません。
例えば、「この制度のメリットとデメリットを教えてください」と質問を投げかけたとして、RAGが制度に関する公式資料、専門家の意見、報道記事などの正確性の高い情報を検索したとします。
しかし、LLMの出力として「この制度には多くのメリットがあります。一方で一部の人にとっては不利益もあるかもしれません。」といったような断定を避ける傾向(保守的な出力の癖)は変えることはできません。
RAGとファインチューニングの違い

RAGは外部データベースを活用して情報を検索し、その情報を基に生成モデルが応答を作成する手法です。
このアプローチにより、常に最新の情報を提供できるのが強みです。一方で似た手法としてファインチューニング(Fine-Tuning)という手法が存在します。
ここではファインチューニングの説明とRAGとファインチューニングの比較をします。
ファインチューニング(Fine-Tuning)とは?
ファインチューニングは、既存のAIモデルに特定のデータを追加学習させることで、特定のタスクやドメインに特化させる手法です。AIモデルの内部パラメータを再調整し、目的のタスクに高精度で対応できるようにします。
RAGとファインチューニングの比較
RAGとファインチューニングの主な違いは、「モデルに知識や情報をどう追加するか」という点です。RAGとファインチューニングには以下のような違いがあります。
| 項目 | RAG | ファインチューニング |
|---|---|---|
| 概要 | 外部データベースから情報を検索し、それをもとにLLMが応答を生成する | 既存のLLMに特定データを追加学習させ、ユーズケースに合わせて調整する |
| 利点 |
|
|
| 用途(具体例) |
|
|
| 更新方法 | データベースを更新 | 新しいデータで再トレーニング |
RAGをAIに活用するメリット
RAGをAIに活用することで期待できるメリットとしては、以下の項目が挙げられます。
- 検索人工知能と生成AIの統合
- 学習データや訓練の効率化
- 応用範囲の拡大
それぞれについて詳しく解説します。
検索AI(人工知能)と生成AIの統合
RAGの活用により、検索AI(人工知能)と生成AIの統合が実現し、より高精度なAIサービスが実現します。検索AIモデルでは、新聞記事やデータベース、Webブログ、社内データベースといった既存のオンラインデータベースから情報を抽出可能です。ただ、これだけではオリジナリティある回答を生み出すことは難しくなります。
一方、生成AIモデルでは、文脈の中で最適かつ独創的な回答を生成できるものの、精度を常時保つことに課題があります。このように既存の検索AIと生成AIモデルの短所を克服するために、それぞれの長所を組み合わせたRAGが開発されました。
多様なデータセットや情報源から検索できるようにすれば、多角的な視点を含む回答の生成も可能になります。
学習データや訓練の効率化
RAGの使用で、AIが必要な学習データや訓練の効率化につながります。既存のAIでは、十分な学習を行うための膨大なデータセットを用意し訓練する必要がありました。訓練の時間やコストも多くなり、開発や導入のハードルが高くなる場合もあります。
そこで、RAGによって最新情報を効率的に活用できれば、LLMの再学習やパラメーターのアップデートにかかるコスト削減が可能です。
応用範囲の拡大
RAGにより生成AIやLLMの応用範囲の拡大につながります。ユーザーが入力した質問の文脈やニーズに合わせて、回答をカスタマイズすることができるからです。
検索AIモデルによる関連キーワードの抽出だけでなく、質問の背景や意図、関連トピックなどから文脈を包括的な把握が可能となります。また、既存の生成AIに見られるような一般的な回答ではなく、時系列も考慮した最適化された回答を生成できるため、活用範囲の拡大が期待されます。
RAGの主な活用例
RAG(検索拡張生成)は、検索AIモデルと生成AIモデルそれぞれの長所を組み合わせることで、単体では実現が難しい高精度かつ信頼性の高い回答生成を可能にする仕組みです。
特に、外部データベースからの情報取得を自動化・最適化できる点が特徴であり、FAQ対応、AIチャットボット、専門文書生成など、さまざまな業務や分野での活用が期待されています。RAGを応用できる分野は幅広く、多くの業界で注目されています。ここでは主な活用例を3つ紹介します。
RAGによるチャットボットアプリケーションの導入
RAGは、コールセンターや社内FAQシステムでのチャットボットアプリケーションに役立ちます。RAGにより、外部データベースに格納された製品情報やサービスガイドをリアルタイムで参照できるため、顧客の質問に対して即座に正確な回答を提供できます。
また、RAGを採用することで社内マニュアルや過去の事例から関連情報を収集し、具体的な解決方法を提示することも可能です。従来のように担当者がマニュアルの該当部分を探し、トラブルに対処するやり方よりも、効率的かつ短時間での対応を実現します。
マーケティング・市場調査の支援
RAGは、マーケティングや市場調査の効率化にも貢献します。生成AIでのリサーチ業務にて、ユーザーの行動履歴や好みなどの関連情報を外部データベースから取得できれば、よりパーソナライズされた商品・サービスの提案が可能です。レコメンデーションシステムとして確立することで、調査にかかる労力を軽減できます。
また、ECサイトやSNSの運用でも、最新のトレンドやアップデート情報を反映した調査結果を組み込みやすくなり、常に最適化された運用が実現します。
大学や研究機関での情報収集と分析の効率化
大学や研究機関では、RAGを用いた論文検索と要約の自動生成が可能です。生成AIを活用した実験計画プロセスの自動化により、人為的ミスや研究計画にかかるコストの削減といった効果が期待できます。
また、RAGが採用されることで担当者がより効率的に情報収集を行えるため、研究品質の向上につながります。さらに、RAGは外部の文献ソースから必要な文章を抜粋する作業をサポートするため、知識を得るプロセスを大幅に効率化できます。
生成AIの導入を検討する際は、RAGをはじめとしたアーキテクチャの特性を理解した上で、自社の目的や要件に最適な技術を選定することが重要です。サービス提供企業の一覧をぜひご活用ください。
RAGをLLMに実装する方法
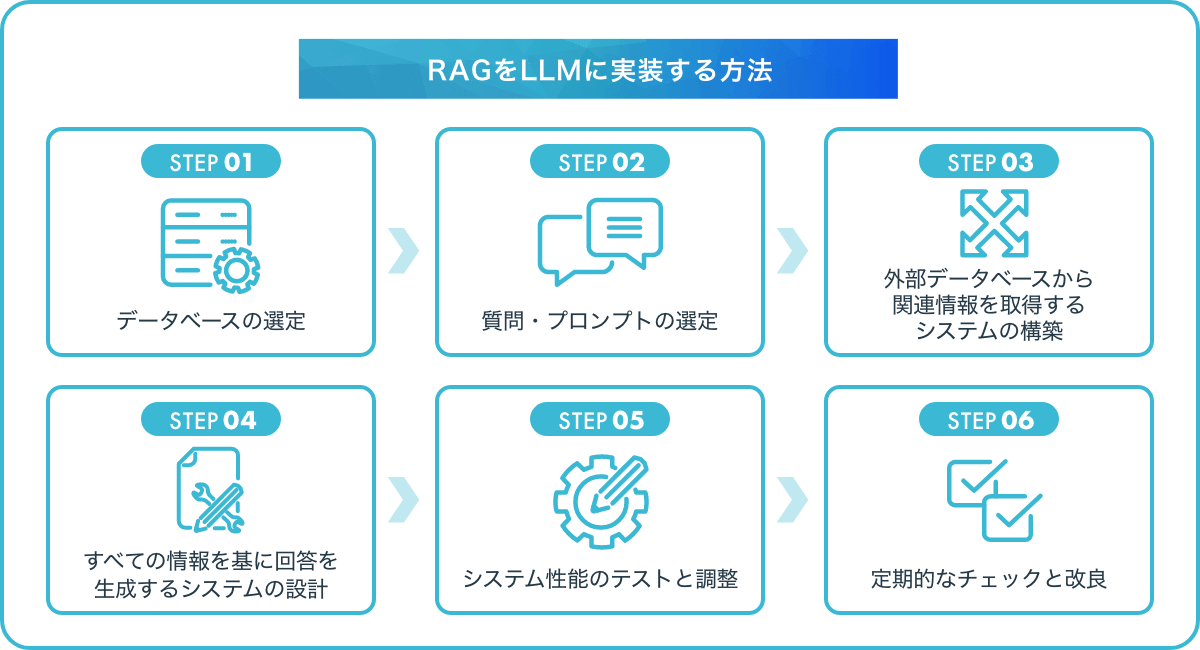
RAGを実装する際の手順は以下の通りです。
STEP01:データベース(知識ソース)を選定する
RAGにおける「データベース(知識ソース)」とは、FAQ、社内ドキュメント、製品マニュアル、Webページ、論文などのLLMが参照すべき検索対象となる情報源を指します。
データを効果的に活用するために、前処理(クリーニング)を行います。具体的には、重複削除・不要語除去・段落分割・フォーマット統一などによって情報を構造化します。
多くの場合、全文検索ではなく、情報を効率よく検索できるようにベクトル検索用のチャンク(小単位の文書)として分割しておきます。
STEP02:質問やプロンプトをベクトルに変換するクエリエンコーダ(Query Encoder)を選定・構築する
クエリエンコーダ(Query Encoder)を用いて、ユーザーからの質問やプロンプトを、意味的特徴をもつベクトル(埋め込み)に変換します。
事前学習されたエンコーダ(例:OpenAI Embeddings、Sentence-BERT、Cohereなど)を用いるのが一般的であり、エンコーダの選定により、検索精度が大きく左右されるため、タスクに適したモデルを選ぶことが重要です。
STEP03:ドキュメントリトリーバー(Document Retriever)を構築する
STEP02でエンコードされた質問ベクトルと、事前にベクトル化された知識ソースの関連文書(チャンク)との類似度を計算し、関連性の高い情報を抽出します。
多くの場合、ベクトルデータベース(例:Zilliz、Upstash、Pinecone、Qdrantなど)を使って高速に類似検索を行います。
スコアリングロジック(Top-k、しきい値、再ランクなど)を工夫することで、検索の精度と適合率を最適化します。
STEP04:すべての情報を基に回答を生成するシステム(Answer Generator)を設計する
検索された関連文書(チャンク)とユーザーの質問をセットでLLMにプロンプトとして渡し、ユーザーが理解できる自然な文章で回答を生成します。
使われるLLMには、ChatGPT、Llama、Claudeなどがあり、LLMは「Retriever + Context」の入力をもとに出力します。
この段階で重要なのは「プロンプト設計(Prompt Engineering)」です。検索結果をどう並べて提示するか、質問の前後に何を付けるかなど、出力の質を左右する要因となります。
STEP05:システム性能のテストと調整を行う
以上のステップで、質問を理解する仕組み(Query Encoder)、情報を探す仕組み(Document Retriever)、回答を作る仕組み(Answer Generator)ができたら、全体を通したテストを行います。
まず、実際のユーザーを想定した質問でテストし、、それぞれに対してシステムが正しく答えられるかを確認します。回答がわかりやすいか、正しい情報を伝えているか、自然な文章になっているかを評価します。
もしうまく回答できていない場合は、「なぜうまくいかなかったのか」を調べて、情報の検索方法や回答を作るAIの設定を細かく調整していきます。こうしたテストと調整を繰り返して、システムを実際に使うユーザーにとって役立つように整えていきます。
STEP06定期的なチェックと改良を続ける
RAGシステムは一度作ったら終わりではなく、実際に使い始めてからも定期的に確認し、使いやすく改善し続けることが大切です。新しい情報(例:社内文書の更新、FAQ追加など)が出てきたらデータベースに新しい情報を反映させることで、常に最新の知識に基づいた回答が可能になります。
システムのログを分析し、「どの質問が多いか」「回答の品質に問題はないか」定期的なモニタリングも行いましょう。
ユーザーからのフィードバックや回答のクリックデータなどをもとに、Retrieverやプロンプトの改善を行うことで、継続的な品質向上を図ることが可能です。こうした継続的な改良を繰り返すことで、長い間ユーザーに満足してもらえるシステムを作ることができます。
RAGの基本的な実装方法は上記の通りで、各手順を進めつつ、課題が出てきたら調整していき、継続的な改良をする必要があります。
まとめ
RAG(検索拡張生成)は、検索AIと生成AI、それぞれのモデルの長所を組み合わせることで、単体では実現が難しかった高精度かつ信頼性の高い回答生成を可能にする仕組みです。
特に、外部データベースからの情報取得を自動化・最適化できる点が特徴で、FAQ対応、AIチャットボット、専門文書生成など、さまざまな業務や分野での活用が期待されています。
生成AIの導入を検討する際は、RAGをはじめとしたアーキテクチャの特性を理解した上で、自社の目的や要件に最適な技術を選定することが重要です。サービス提供企業の一覧をぜひご活用ください。
アイスマイリーでは「生成AI のサービス比較と企業一覧」を提供しています。最新のAIサービス動向を把握し、比較検討するために以下よりぜひご活用ください。
よくある質問
RAGの意味は何ですか?
RAGは「Retrieval Augmented Generation」の頭文字を組み合わせた単語で、「検索拡張生成」を意味します。
RAGは、外部データベースから関連情報を取得(Retrieval)し、質問やプロンプトに対する回答を生成(Generation)する仕組みです。 最新情報や外部の関連データを参照できるため、より正確で精度の高い回答を生み出すことが可能です。
RAGは日本語対応の生成AIで使えますか?
RAGは日本語対応の生成AIでも使用できます。現在は、LLMとLangChainを使ったRAGが一般的で、手元の環境でも試せるケースが多いでしょう。
DXトレンドマガジン
メールマガジン登録
業務の課題解決に繋がる最新DX・情報をお届けいたします。
メールマガジンの配信をご希望の方は、下記フォームよりご登録ください。登録無料です。


AI・人工知能記事カテゴリ一覧
AI・人工知能サービス
- AIエージェント
- LLM
- AI研究開発
- ChatGPT
- 画像生成AI
- 生成AI
- RAG
- DX推進
- おすすめAI企業
- チャットボット
- ボイスボット
- 音声認識・翻訳・通訳
- 画像認識・画像解析
- 顔認証
- AI-OCR
- 外観検査
- 異常検知・予知保全
- 自然言語処理-NLP-
- 検索システム
- 感情認識・感情解析
- AIモデル作成
- 需要予測・ダイナミックプライシング
- AI人材育成・教育
- アノテーション
- AI学習データ作成
- エッジAI
- IoT
- JDLA
- G検定
- E資格
- PoC検証
- RPAツール
- Salesforce Einstein
- Watson(ワトソン)
- Web接客ツール
- サプライチェーン
- メタバース
- AR・VR・デジタルツイン
- MI
- スマートファクトリー
- データ活用・分析
- 機械学習
- ディープラーニング
- 強化学習
- テレワーク・リモートワーク
- マーケテイングオートメーション・MAツール
- マッチング
- レコメンド
- ロボット
- 予測
- 広告・クリエイティブ
- 営業支援・インサイドセールス
- 省人化
- 議事録自動作成
- 配送ルート最適化
- 非接触AI
業態業種別AI導入活用事例
今注目のカテゴリー
ChatGPT連携サービス

チャットボット

AI-OCR

生成AI
ChatGPT連携サービス
チャットボット
AI-OCR












FOLLOW US
SNSをフォローして、最新情報をチェックできます!
清水建設、鉄筋の加工・組立作業に「フィジカルAI」導入。スイスM…

クラダシ「Claude」を全社展開。特有業務の自動化の推進および…

Sakana AI、マルチエージェント基盤「Sakana Fug…
デンソーテン、独自の埋め込みモデル学習技術により車載エッジでRA…

ブロックチェーンとは?仕組み・種類・活用事例をわかりやすく解説

2026年上半期トレンドワードランキングをPR TIMESが公開。「AI」が初の総合1位、「フィジカルAI」は前年比46倍超

NECとJR東日本、「みどりの窓口AI対応サービス」の実現に向け実証実験を実施

【CES 2026完全まとめ】AI実装がもたらす5つの最新トレンドと受賞例

カゴメなど5者、AI選果機の共同開発と実証の成果を発表。トマトの廃棄ロスを30%低減
TBSラジオ、AIで音声CMを生成する「デモCMジェネレーター」を公開。音声広告企画を支援
AI製品・ソリューションの掲載を
希望される企業様はこちら