

深層生成モデルの4つの代表モデルと画像生成サービスとの関係性について解説
最終更新日:2024/02/07
 深層生成モデルのと画像生成サービスとの関係性
深層生成モデルのと画像生成サービスとの関係性
AIが学習を重ねて全く新しい画像を生成する深層生成モデルは、近年話題となっている画像生成サービスの技術を根幹から支えています。深層生成モデルの発展は、今後の画像生成サービスの発展に必要不可欠だといえます。
生成モデルとディープラーニングを掛け合わせた深層生成モデルの登場によって、AIにおける画像生成の分野は飛躍的な発展を遂げており、さまざまな技術者がAIによる画像生成サービスを開発・提供しています。特に2022年は複数の画像生成サービスが一般公開され、これまでには無かった新しい体験を多くのユーザーが歓迎しました。
画像生成AIはまだまだ発展途上の分野ではありますが、今後さらに精度が向上していけば、ビジネスにも具体的に応用されていく可能性が十分に考えられます。
深層生成モデルには、派生形を含めると膨大な種類があります。本記事では、生成モデルの概要や、深層生成モデルの中でも代表的な「VAE」「GAN(敵対的生成ネットワーク)」「フローベースモデル」「拡散モデル」の4つを紹介します。
生成モデルとは?

生成モデルとは、「AIが元画像を学習し、そのデータの特徴を持った新たなデータを生成するモデル」のことです。
例えばAIにあるイラストレーターの画像を訓練データとして与え、画像の特徴を学習させると、学習後のAIはそのイラストレーターの特徴を持つイラストを生成できるようになります。
同様のイメージで、人間の顔を学習させると、実際には存在しない空想上の人間の顔を、AIによってリアルに生成することも可能です。
生成モデルには「確率的生成モデル」という考え方があります。確率的生成モデルとは、「現実に存在するデータの裏側には、そのデータを生成するためのモデルがある」という前提で捉えられます。また、そのデータは確実性をもって生成されるわけではなく、一定の確率で揺らぎが発生する(確率分布が存在する)と考えられます。
例えば、ある1枚の猫の画像があった時、「その猫の画像は何らかの生成モデルによって生まれたものである」という前提で捉えるのが、確率的生成モデルの考え方です。この時、猫の画像は100%現在の姿のまま生まれると決められていたわけではなく、一定の確率の揺らぎの中で生まれたとみなされます。
識別モデルとの違い
生成モデルがデータを「範囲で学習する」仕組みであるなら、識別モデルはデータを「線で分割して学習する」という違いがあります。
例えば、赤いりんごと青いりんごが10個ずつあったとき、生成モデルの場合は「この辺りまでは赤いりんご(青いりんご)のデータがある範囲だ」という認識の方法を取ります。つまり、同系統のデータが分布している範囲をそれぞれ学習するのが生成モデルです。
一方の識別モデルは、「この線からこちら側には赤いりんごのデータがある」「この線からあちら側には青いりんごのデータがある」というように、カテゴリ別に条件付きで明確な線引きをします。データをクラスで分類し、各クラス別に属する確率をモデルに落とし込んだものが識別モデルです。
識別モデルはカテゴリ別に分類してしまうため、「赤いりんご」「青いりんご」以上の結果は得られません。しかし、生成モデルであれば「赤いりんごのデータ範囲と、青いりんごのデータ範囲の大体中間くらい」を予測することで、それぞれの特徴を持った全く新しいデータを生成できます。
深層生成モデルとは?

深層生成モデルとは、ディープラーニング(深層学習)と生成モデルを掛け合わせたモデルです。深層生成モデルは、英語で「Deep Generative Model」と表現されます。
深層生成モデルにおいては、ディープニューラルネットワークと呼ばれる複雑性の高いディープラーニングを使ってAIに学習させることで、従来の単純な機械学習による生成モデルよりも高度な画像を生成できるという特徴があります。AIが入力されたデータに対して複数の出力を返せるため、複雑な判断が可能になる点が特徴です。
深層生成モデルの代表的なモデルとして、「VAE」「GAN(敵対的生成ネットワーク)」「フローベースモデル」「拡散モデル」などが挙げられます。それぞれのモデルの特徴については後述します。
深層生成モデルの特徴

深層生成モデルの特徴として、画像や音声などの複雑性の高いデータ分布を有するデータ群から生成モデルを学習することで、まるで本物のように高品質なデータを生成できます。
冒頭のイラストレーターの例では、複数の特徴を持つ複雑性の高いデータを教師データとして用いています。このような高次元のデータを複数件与えることで、AIはさまざまな特徴を学び、AI自身が新たなデータを生み出せるようになるのです。
上記ではイラストレーターの例を紹介しましたが、音楽などでも同様の疑似データの生成が可能です。深層生成モデルであるアーティストの楽曲を複数曲AIに学習させると、AIはそのアーティストの特徴を理解し、新たな楽曲を生成できるようになります。
画像生成サービスと深層生成モデルの関係性

画像生成サービスとは、ある画像をAIに読み込ませると、その画像の特徴を持った新たな画像をAIが自動的に生成してくれるサービスのことです。
2022年に入ってから、AIによる画像生成サービスは急速な広がりを見せています。2022年8月にはアメリカのStability Aiによって「Stable Diffusion」がオープンソース化されるなど、世界中で画像生成サービスに関する話題は尽きません。
この画像生成サービスには、前述の深層生成モデルが活用されています。さまざまなユーザーが読み込ませたデータをAIが学習し続けることで、より高精度で特徴を捉えた疑似データを生み出せるAIへと成長していきます。画像生成サービスと深層生成モデルは、切っても切り離せない技術です。
当初はユーザーの意図とは異なる画像が生成されていた場合でも、深層生成モデルによって学習を重ねることで、だんだんとユーザーの投入した画像の特徴を的確に捉えた画像を生成できるように変化していくのです。
深層生成モデルの代表例

深層生成モデルの代表例として、VAE、GAN(敵対的生成ネットワーク)、フローベースモデル、拡散モデルなどが挙げられます。VAEもGANもAIに新たな画像を生成させる手法である、という点では同様ですが、学習方法が異なります。
また、VAEやGANに比べると知名度はやや低くなりますが、フローベースモデルと拡散モデルにも、それぞれのメリットがあります。ここでは、代表的な4つの深層生成モデルについて、仕組みや特徴を詳しく解説します。
VAE
VAEとは「variational autoencoder」の略称で、深層生成モデルの中でもGAEと並んでよく利用されています。「エンコーダー」と「デコーダー」という2種類のモデルを並べて、入力画像の圧縮と復元を行うことで新たな画像を生成するのが、VAEの基本的な仕組みです。
VAEによる画像生成では、入力された画像を「エンコーダー」で圧縮します。この圧縮した画像に対して「z」と呼ばれる潜在変数を入力した上で、「デコーダー」で画像を復元すると、新たな画像が生成されるという流れです。つまり、VAEにおける生成器の役割を果たすのはデコーダーです。
VAEによって生成される画像は、解像度がやや低く、ぼやけたイメージの画像になりやすい点が特徴です。これはVAEが生成後の画像と元画像を比較する際にピクセル単位で比較するため、解像度が低くぼやけている方が、元画像との一致度が高くなるという理由によるものです。
GAN(敵対的生成ネットワーク)
GAN(敵対的生成ネットワーク)は、英語で「Generative Adversarial Networks」と表現されます。2種類のニューラルネットワークを競わせてAIの学習を行う点が特徴で、このような性質から「敵対的生成ネットワーク」と呼ばれることもあります。
GAN(敵対的生成ネットワーク)の仕組みは、よくブランド品の偽造業者と鑑定士の関係に例えられます。偽のブランド品を作って顧客を騙そうとしている偽造業者と、偽のブランド品を鑑定する鑑定士は、お互いに相手を欺こうとします。
偽造業者は鑑定士に偽物だと見抜かれないような、精度の高い偽ブランド品を作ろうと努力します。一方の鑑定士は、どれほど精巧な偽ブランド品でも見破るために、鑑定のスキルを高めるように努力します。
このような双方の競い合いを、「Generator(生成器)」と「Discriminator(識別器)」の2つのニューラルネットワークで繰り広げるのが、GANの基本的な仕組みです。
フローベース生成モデル
フローベースモデルとは、尤度(ゆうど)を明確に示す形でAIの学習を行うモデルです。尤度とは、「ある物事が起こる可能性」を示す値のことです。VAEやGANは尤度を明示せずに学習するため、フローベース生成モデルはVAEやGANとは考え方自体が少し異なっています。
VAEやGANでは、基本的に2つのモデルを学習する必要があります。VAEでは「エンコーダー」と「デコーダー」、GAEにおいては「Generator」と「Discriminator」が該当します。しかし、フローベース生成モデルの場合は、新たな画像を生成する過程で2つのモデルを学習する必要がなく、「データ変形関数」と呼ばれる数値のみを学習するだけで、新たな画像を生成することが可能です。
これは、新たな画像を生成するための入力データと生成器の間に存在するデータ処理を、「データ変形関数」だけで完結させることができるためです。フローベース生成モデルにおいては、データの逆変換に対応しています。
拡散モデル
拡散モデルは、画像生成サービスなどで近年利用される機会が増えてきている生成モデルです。拡散モデルの学習は、「ノイズを追加する関数」と「画像を復元するネットワーク」の2種類を活用して行われます。
AIに元画像を与えると、ノイズを追加する関数によって、元画像にノイズが追加されて画像は劣化します。その画像を復元するネットワークによって、ノイズを除去し、元の画像に近づける形で復元します。このとき、元画像とノイズを除去した画像の差異を最小に近づける処理をトレーニングと位置づけて、拡散モデルにおけるAIは学習を重ねていきます。
拡散モデルは生成する画像の幅が広い点が特徴的で、今後、フローベース生成モデルと並んで利用が広がっていく可能性が指摘されています。VAEやGANよりも高解像度の画像生成に成功している研究もあり、現状ではVAEやGANの知名度には及びませんが、将来性があるモデルのひとつです。
深層生成モデルを活用した画像生成サービス
深層生成モデルを活用した画像生成サービスとして、DALL-E2やImagen、Midjourney、Stable Diffusion(Dream Studio)などが挙げられます。
画像生成サービスが注目を集め始めたのは2022年のことで、まだ一般的に使われるようになってから日が浅いため、今後もさまざまなサービスが登場するものと考えられます。技術的にもこれからさらなる発展が期待されており、今後さらに画期的なサービスが登場する可能性もあります。
ここでは、現在世界で提供されている画像生成サービスのうち、知名度の高い4つのサービスを紹介します。
DALL-E2
DALL-E2は、オープンソースで提供されている画像生成サービスです。拡散モデルをベースにした深層生成モデルによる画像生成サービスで、Webサイトからアカウントを作成するだけで利用でき、簡単に新たなAI画像を生成できます。
Webサイト上の検索バーにテキストで具体的な文章を入力すると、AIがテキストの内容を解釈し、新たな画像を生成してくれるという仕組みです。例えば「幻想的な花畑を背景にダンスする10代少女の現代絵画」などと入力すると、それぞれの要素をAIが解釈して、過去の学習を参考に結果を返します。
現在のところ完全無料で利用できますが、利用できる回数には制限があり、登録した月は50クレジット、翌月以降は毎月15クレジットが付与されます。
クレジットは、AIが画像の生成を完了した時点で消費されるため、万が一エラーや規約違反などで生成に失敗した場合、クレジットは消費されません。
Imagen
Imagenは、Google Researchが提供する画像生成サービスです。前述のDALL-E2と同様に拡散モデルを使った深層生成モデルで、同社の発表によれば、「DALL-E2に比べて人間に好まれる結果になった」と述べられています。
Imagenも一般的な画像生成サービスと同様に、テキストによる説明をAIに付与することで、AIがテキストの内容を解釈し、新しい画像を生成する形式です。同社のテスト結果では、写実的でリアルな写真に近い画像から、加工済みのような画像まで、さまざまパターンの画像を生成できると発表されています。
ただし、Imagenは2022年12月時点で一般公開されていません。Google社によれば、現状においてはImagenがもたらす強すぎる影響を懸念しているということです。AIに関する法整備などがまだ十分に進んでいない現状では、Imagenを使って生成した画像を何らかの方法で悪用するなどのリスクも考えられるため、今後の展開が待たれるところです。
Midjourney
Midjourneyは、元NASAの技術者などのメンバーが集まって開発された画像生成サービスです。現状ではインスタントメッセージやビデオ通話が可能なアプリ「Discord」に登録しているユーザーが利用可能なサービスで、全てのユーザーに公開されているわけではありません。
Midjourneyは拡散モデルが使われているといわれていますが、現在のところ、開発者による明言はされていない状況です。
無料で25枚まで利用できるため、まずは画像生成サービスに触れてみたいという方や、どのような画像を生成できるのか確認してから有料契約したいという方にもおすすめです。
有料プランはベーシック、スタンダード、コーポレートの3種類用意されており、ベーシックは月10ドルで200枚まで、スタンダードは月30ドルで無制限の画像生成が可能です。コーポレートは年600ドルで、生成した画像を企業向けの商用利用ができる点が特徴です。
Stable Diffusion(Dream Studio)
Stable Diffusionも、他の画像生成サービスと同様に2022年に登場しました。拡散モデルをベースにしていますが、より効率性を高めて精度の高い画像を生成できるようにアプローチした「潜在拡散」と呼ばれるアルゴリズムを採用している点が特徴です。
潜在拡散の基本的な考え方は拡散モデルと同様で、元画像に付与されたノイズを徐々に取り除いていくことで学習するモデルです。しかし、従来の拡散モデルでは、処理の構造上、トレーニングや推測に膨大な時間を要するというデメリットがありました。
そこで、VAEの潜在空間の考え方を拡散モデルに取り入れたのが「潜在拡散」です。つまり、潜在拡散とは、拡散モデルをベースにVAEの一部分を組み込んだモデルと説明することができます。
「Stable Diffusion」は現在のところ無料で利用できますが、より高速な生成をしたい場合は、細かい調整を行いたい場合は、「DreamStudio」というサービスを利用する必要があります。ただし、DreamStudioも登録時に200クレジットが付与されるため、制限はあるものの無料で利用することは可能です。
まとめ

生成モデルを活用することで、AIに学習させたデータの特徴を持つ、全く新しい画像を生成できます。最近では画像生成サービスも次々と登場しており、画像生成サービスと深層生成モデルは切っても切れない関係にあります。
昨今の画像生成AIに使われるAI生成モデルは「拡散モデル」が中心です。拡散モデルはVAEやGAN、フローベース生成モデルなどに比べて高品質な画像を生成できることから注目を集めており、多くの技術者が拡散モデルをベースに画像生成サービスを開発していると考えられます。今後の発展が予想される画像生成AIと、新たな深層生成モデルの派生モデルから目が離せません。
AIsmileyでは、専門的な知識を必要とする機械学習・深層学習のモデルをマウス操作で簡単に作成できる「AIモデル作成サービスに関する情報」を紹介しています。AIの学習モデルについてさらに詳しく知りたい方は、下記の資料一括請求ページをご覧ください。
DXトレンドマガジン
メールマガジン登録
業務の課題解決に繋がる最新DX・情報をお届けいたします。
メールマガジンの配信をご希望の方は、下記フォームよりご登録ください。登録無料です。


AI・人工知能記事カテゴリ一覧
AI・人工知能サービス
- AIエージェント
- 生成AI
- ChatGPT
- Gemini
- Claude
- LLM
- AI研究開発
- 画像生成AI
- RAG
- DX推進
- おすすめAI企業
- チャットボット
- ボイスボット
- 音声認識・翻訳・通訳
- 画像認識・画像解析
- 顔認証
- AI-OCR
- 外観検査
- 異常検知・予知保全
- 自然言語処理-NLP-
- 検索システム
- 感情認識・感情解析
- AIモデル作成
- 需要予測・ダイナミックプライシング
- AI人材育成・教育
- アノテーション
- AI学習データ作成
- エッジAI
- IoT
- JDLA
- G検定
- E資格
- PoC検証
- RPAツール
- Salesforce Einstein
- Watson(ワトソン)
- Web接客ツール
- サプライチェーン
- メタバース
- AR・VR・デジタルツイン
- MI
- スマートファクトリー
- データ活用・分析
- 機械学習
- ディープラーニング
- 強化学習
- テレワーク・リモートワーク
- マーケテイングオートメーション・MAツール
- マッチング
- レコメンド
- ロボット
- 予測
- 広告・クリエイティブ
- 営業支援・インサイドセールス
- 省人化
- 議事録自動作成
- 配送ルート最適化
- 非接触AI
- GPU
業態業種別AI導入活用事例
今注目のカテゴリー
チャットボット

AI-OCR

フィジカルAI

生成AI
チャットボット
AI-OCR
フィジカルAI














FOLLOW US
SNSをフォローして、最新情報をチェックできます!
清水建設、AIロボットの研究開発を本格化。現場巡回や塗装作業で実…

SpaceXAI、最新モデル「Grok 4.5」を提供開始。コー…

Cloverse、アパレル特化型AI「Clovia」提供開始。撮…
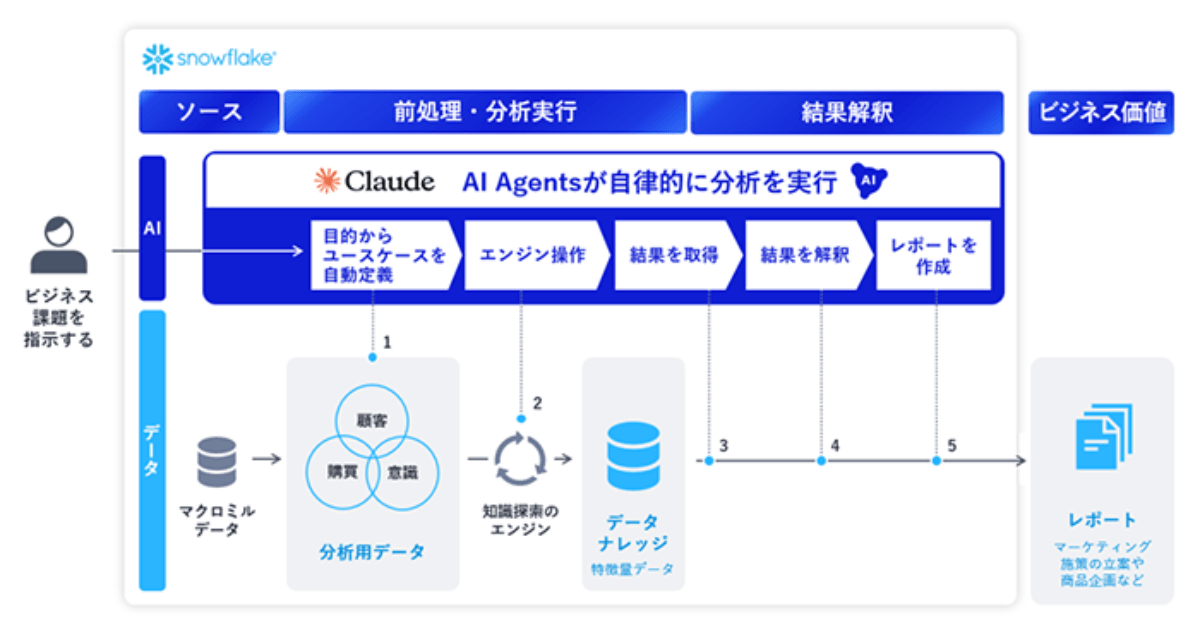
NEC、Anthropic協業による「NEC AIインサイトレポ…

キッセイコムテック、ペーパーレス会議システムに生成AI活用の資料検索・要約機能を搭載。ANAホールディングスの経営会議で導入

ソフトバンクと安川電機、「AIデータセンターGPUクラウド」を活用し、柔軟物体ハンドリングシステムを実証

Anthropic、Slack上で動作する新機能「Claude Tag」発表。チーム利用可能で自律的にタスクを処理

Noetra、国産マルチモーダル基盤モデルの研究開発を本格始動。ソニー・SB・NEC・ホンダなどと連携

Grokプロンプトの書き方完全ガイド|業務で使える例文集と作り方のコツ

サイバーセキュリティのAI自動化とは?メリット・セキュリティ戦略を解説
AI製品・ソリューションの掲載を
希望される企業様はこちら