法人向けAIエージェント「OfficeAI社員」 ネオス株式会社
OfficeAI社員は、人間の社員と同様に、業務サポート・情報提供・ドキュメント作成支援などの役割を担い、対話を通じて組織内の効率化を図ります。
| 利用料金 | 初期費用 | 無料プラン | 無料トライアル |
|---|---|---|---|
| お問合せください | お問合せください | お問合せください | お問合せください |
一括資料請求なら、導入の比較検討が
スムーズに行えます!
利用料金・初期費用・無料プラン・トライアルの有無などを、一覧で比較・確認できるページです。サービスを比較・検討後、希望条件に合うものが見つかりましたら、下記のボタンよりご請求いただけます。

OfficeAI社員は、人間の社員と同様に、業務サポート・情報提供・ドキュメント作成支援などの役割を担い、対話を通じて組織内の効率化を図ります。
| 利用料金 | 初期費用 | 無料プラン | 無料トライアル |
|---|---|---|---|
| お問合せください | お問合せください | お問合せください | お問合せください |

ドキュメントを検索・分析可能な形に整備KIBIT Libriaは、社内に散在する非構造ドキュメントをAIで整理・検索可能にし、ナレッジ活用や業務効率化、意思決定支援につなげるドキュメント利活用DXソリューションです。
| 利用料金 | 初期費用 | 無料プラン | 無料トライアル |
|---|---|---|---|
| 有償トライアル(2~3か月) 実際のお客様データを使用してお試しいただくことが可能です。 FRONTEOクラウド:200万円、オンプレ:250万円 詳細はお気軽にお問い合わせください。 |
- | - | あり ※準備中 |

メロンが提供する「異常検知AI」は、機械や工場設備のIoTセンサーデータやPLCの稼働ログなどから、様々な異常の予兆を検知し、故障を未然に防ぎます。その他にも不正アクセスや不正取引の検出といったサイバーセキュリティにも活用可能です。
| 利用料金 | 初期費用 | 無料プラン | 無料トライアル |
|---|---|---|---|
| お問い合わせください | お問い合わせください | お問い合わせください | お問い合わせください |

メロンが提供する需要予測AIシステム『KISS』は、過去データや外生変数から、将来の商品需要や売上、消費量などを高精度に予測し、様々な業務を最適化します。
| 利用料金 | 初期費用 | 無料プラン | 無料トライアル |
|---|---|---|---|
| お問い合わせください | 50万円~ | お問い合わせください | お問い合わせください |

~生成AI×自社データ連携時のRAG回答精度向上を支援~ソフトバンク株式会社が提供する「RAGデータ作成ツール」は 生成AIの回答精度の改善において作業負荷が高い「データ作成」や「回答精度評価」を ワンストップで効率化し、回答精度の向上を支援します。
| 利用料金 | 初期費用 | 無料プラン | 無料トライアル |
|---|---|---|---|
| 案件詳細を伺ってお見積りいたします。 | なし | なし | なし |
![]()
![]()

高精度RAG × 独自データ × プリセットエージェントで実現する、 プロフェッショナル向けの業務AI 実装支援プラットフォーム。
| 利用料金 | 初期費用 | 無料プラン | 無料トライアル |
|---|---|---|---|
| 用途に合わせて、最適なプランを提供します。お問合せください。 | お問合せください | お問合せください | お問合せください |

株式会社言語理解研究所(ILU)が提供するAPIサービス「データ構造化ソリューション『DX-laei』(ディーエックス レイ)」は、AIエージェントやRAGの業務活用において課題となる「回答精度の低さ」や「利用者にプロンプト知識が求められる」といった運用上の問題に対し、日本語に特化した自然言語処理技術でアプローチします。 「DX-laei」は、ドキュメントの構造化処理に加え、ユーザーの質問意図を意味的に再構成し、最適な検索クエリへ変換する機能を備えています。これにより、生成AIの精度を左右する“入力精度”と“検索対象の整備”の両面から、RAGやAIエージェントの回答品質を向上させます。
| 利用料金 | 初期費用 | 無料プラン | 無料トライアル |
|---|---|---|---|
| 提供プランについて ご提供内容・サポート範囲の違いに応じて、以下の3プランをご用意しています。 【ベーシック】 汎用的な高精度ドキュメント構造化および検索クエリ生成APIをご利用いただけるプラン。 DX-laeiの基本的な機能を、高精度でありながらコストを抑えてご利用いただけます。 【アドバンス】 ベーシックの機能に加え、基本的なカスタマイズ(辞書構築・AI学習)に対応したプラン。 個社最適化することで、複雑な図表や画像が含まれたドキュメントの構造化処理が可能です。 【プレミアム】 アドバンスの内容に加え、より高度なカスタマイズ(高精度AI学習・フォロー支援)に対応するプラン。 販売サービス連携やオンプレミス環境への対応など、個別要件に柔軟にお応えします。 ベーシックプランは、月額25万円(税別)~にてご提供しております。 詳しくはお問い合わせください。 |
お問い合わせください | なし | なし |
株式会社富士テクニカルリサーチが提供する「Galaxy-Eye Episode」は、社内に点在する様々な文書を集約したデータベースを構築し、社内文書の検索・文書の自動生成が可能なローカル対応文書管理AIシステムです。
| 利用料金 | 初期費用 | 無料プラン | 無料トライアル |
|---|---|---|---|
| お問合せください | お問合せください | なし | お問合せください |

スキルアップNeXtが提供する「AI開発・伴走支援・内製化支援」は、技術伝承等の機密情報を扱うRAG環境、AOAIを用いたRAG環境、画像認識を活用したプロダクト開発等にも柔軟に対応します。
| 利用料金 | 初期費用 | 無料プラン | 無料トライアル |
|---|---|---|---|
| お問合せください | お問合せください | お問合せください | お問合せください |

KIZASHIが提供する「ChatGPTマスター養成講座 AIリスキリング研修」は生成AI時代に必要3つのスキル「リスキリングマインドセット」「AIリテラシー」「AIスキル」を取得できます
| 利用料金 | 初期費用 | 無料プラン | 無料トライアル |
|---|---|---|---|
| 100,000円 | なし | なし | なし |
![]()

ナレフルチャットは、クローズド環境でセキュアに利用できる企業向けの対話型生成AIチャットツールです。 AIリテラシーの向上から業務効率の改善まで、ナレフルチャットが生成AIの力を最大限に引き出し、生成AI活用をトータルでサポートします。
| 利用料金 | 初期費用 | 無料プラン | 無料トライアル |
|---|---|---|---|
| 月額40,000円/1企業 ユーザ数無制限 |
なし | なし | あり |
![]()

株式会社M2DSが提供する「DXセカンドオピニオン」はDX推進している企業や、これからスタートする企業を対象にDXにおける自社課題やゴール、進捗状況を客観的に診断・アドバイスするサービスです
| 利用料金 | 初期費用 | 無料プラン | 無料トライアル |
|---|---|---|---|
| 0円 | 0円 | あり | あり |

トランシンクが提供する音声・画像・動画データセットは、既存パッケージから必要なだけ購入することができます。ゼロからプロジェクトを立ち上げることなく、必要なだけ購入し、AIモデルの開発ができます。
| 利用料金 | 初期費用 | 無料プラン | 無料トライアル |
|---|---|---|---|
| 音声コーパス:15,000円 / 時間 人物写真画像収集:300円 / 画像 |
なし | なし | あり |

世界中のデータとパワフルなAIで隠れたビッグディールを発掘。
| 利用料金 | 初期費用 | 無料プラン | 無料トライアル |
|---|---|---|---|
| 投資家プラン:1名あたり月額50,000円 企業プラン:ご相談ください |
なし | Chrome拡張機能で一部体験可能 | あり(14日間) |

創薬研究の大幅な効率化・加速化・成功確率向上を支援株式会社FRONTEOが提供する「Drug Discovery AI Factory」は、創薬とAIへの豊富な知見を持つ研究者が、自社開発のAIエンジンを用いて新規性の高い標的分子やバイオマーカーの探索・評価、適応症提案、シーズ評価などのエビデンスに基づく仮説を生成・提供します。
| 利用料金 | 初期費用 | 無料プラン | 無料トライアル |
|---|---|---|---|
| お問合せください | お問合せください | お問合せください | お問合せください |

予想外の論文を発見し、新たな着想を得る株式会社FRONTEOが提供する「KIBIT Amanogawa」は、単語や文章を入力すると、AIがPubMed内の膨大なデータから、関連性の高い情報を検出します。キーワード検索では発見できない情報が見つかり、創薬研究における客観的・網羅的な分析を実現します。
| 利用料金 | 初期費用 | 無料プラン | 無料トライアル |
|---|---|---|---|
| お問合せください | お問合せください | お問合せください | お問合せください |

日常のモニタリング業務の工数を大幅に削減するとともに、内在するリスクを可視化することで経営危機から企業を守ります
| 利用料金 | 初期費用 | 無料プラン | 無料トライアル |
|---|---|---|---|
| お問合せください | お問合せください | お問合せください | お問合せください |

EITAIテクノロジーズ株式会社が提供する「alivorte(アリヴォルテ)」は、メールでのお客様対応の品質向上に貢献することのできるクラウドサービスです。また、担当者ごとのメール対応状況(受信・返信・未返信の件数など)も可視化します。
| 利用料金 | 初期費用 | 無料プラン | 無料トライアル |
|---|---|---|---|
5名様まで: 9万円 6名様以降〜: 9万円 + 9,600円×利用人数−5 |
なし | あり | あり |

AI開発・導入からビジネスコンサルティング、書籍出版まで幅広い領域での実績があるデータサイエンティストが、AI・データ活用に関して川上から川下までフルラインナップでご支援いたします。
| 利用料金 | 初期費用 | 無料プラン | 無料トライアル |
|---|---|---|---|
| お問合せください | お問合せください | お問合せください | お問合せください |

ソフトバンク株式会社が提供する「TASUKI Annotation」は社内データの構造化の代行により、RAGの検索精度向上の支援を行います。特に、ChatGPT等のLLMが解釈を苦手としている図表などの情報も回答させることが可能になります。
| 利用料金 | 初期費用 | 無料プラン | 無料トライアル |
|---|---|---|---|
| 案件詳細を伺ってお見積りいたします。 | なし | なし | なし |


プロダクト資料をまとめて
比較・確認したい方はこちら

| 製品名 |

EmmaTools |

AI搭載・自動英文校正ツールTrinka |
AI suite(エーアイスイート) |

SpectA KY-Tool |
|---|---|---|---|---|
| 機能 |
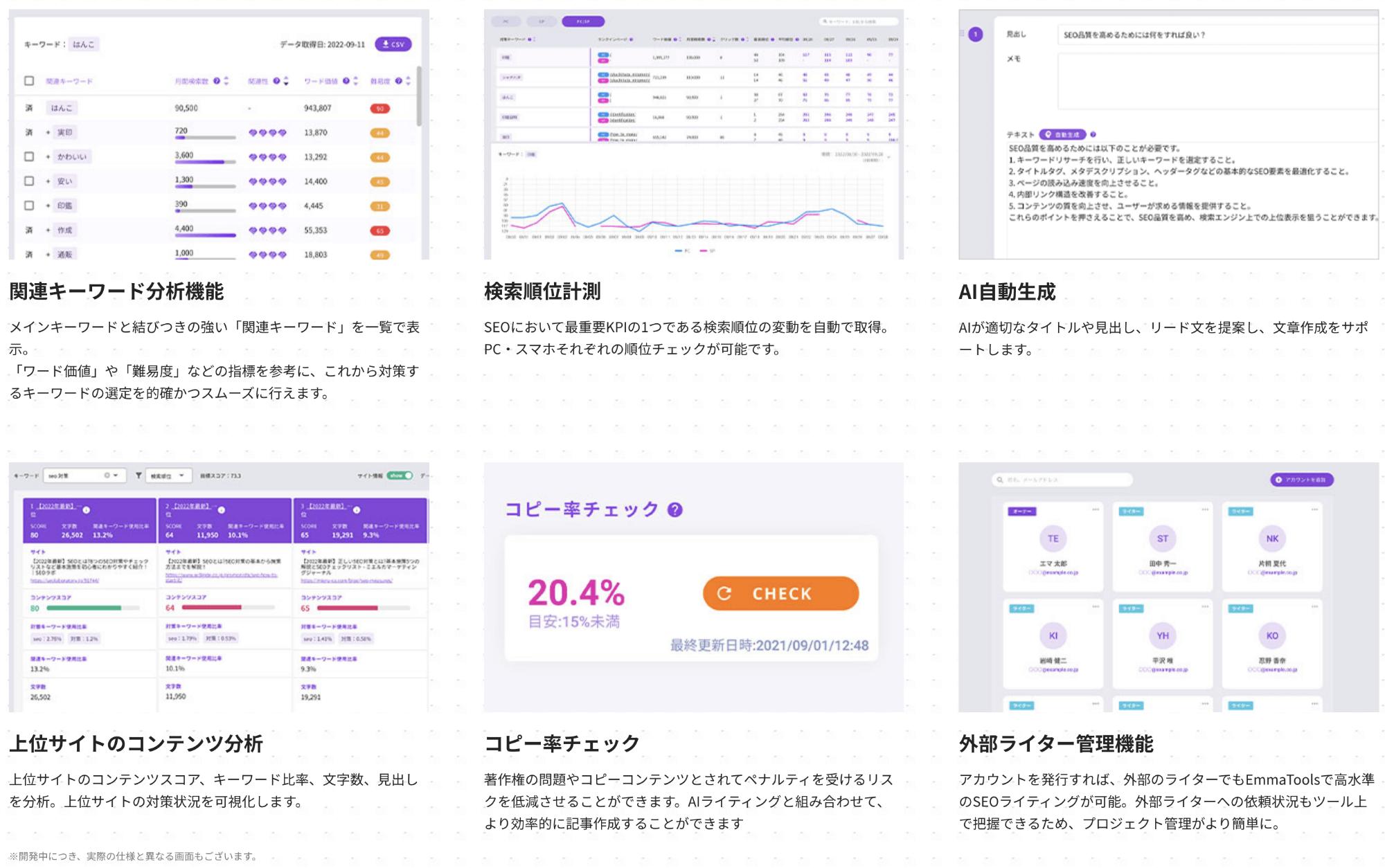
コンテンツの“足りない”がわかる AI文章作成搭載のSEOライティングツール |
|
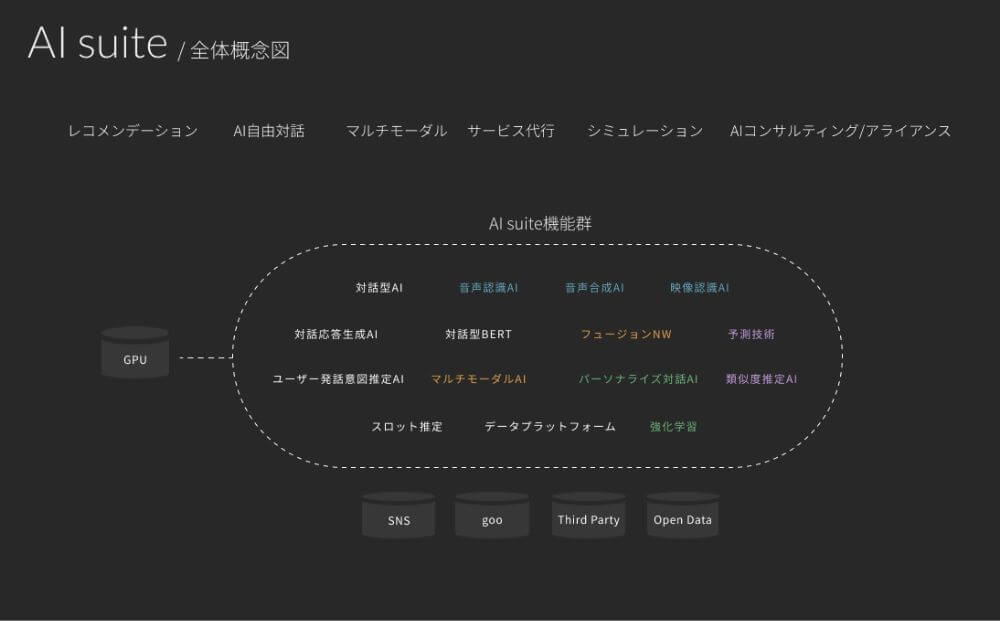
さまざまなAI技術と連携ができる機能を持つAPI群 |
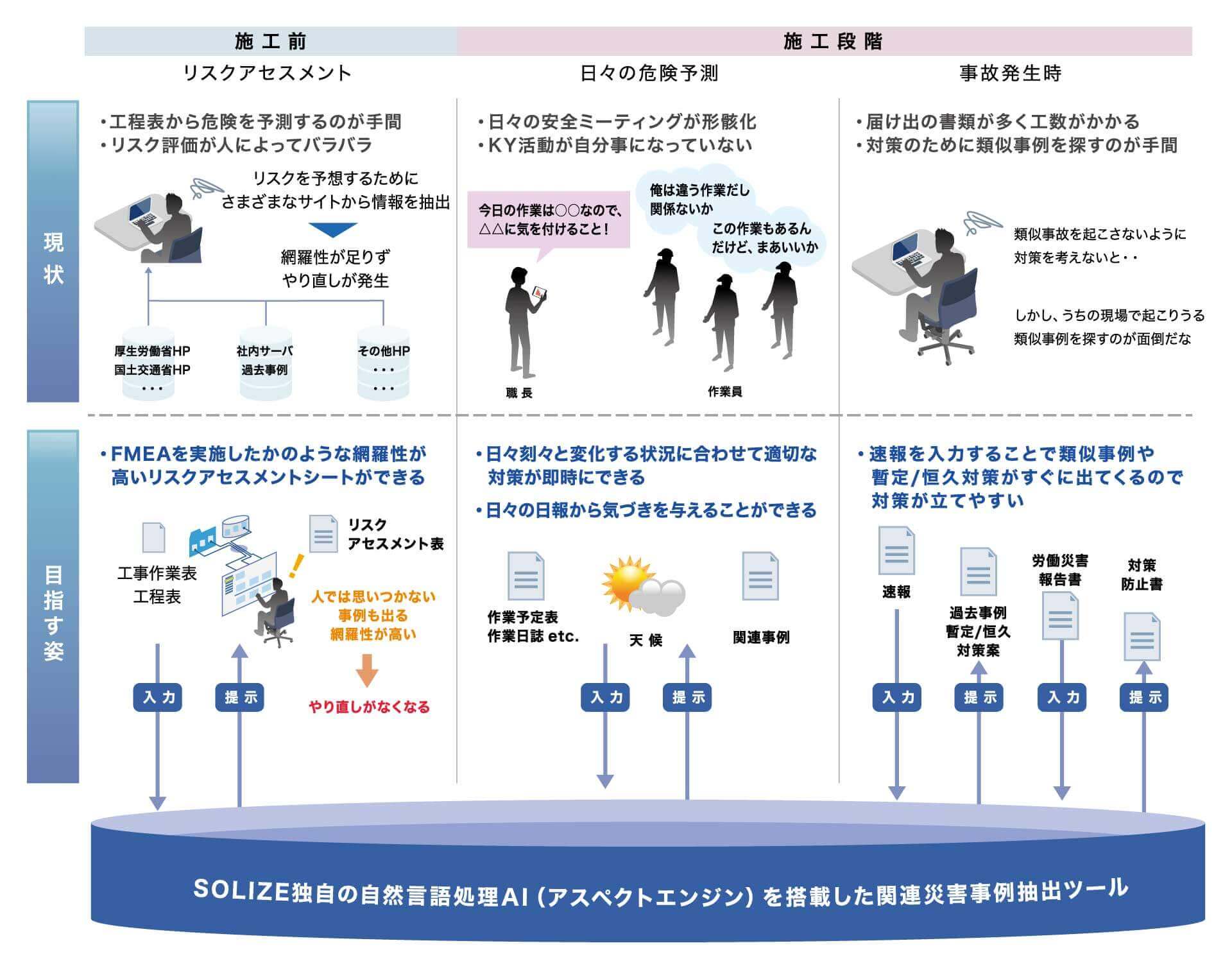
安全管理業務における危険予知の高度化・現場改善をAIがサポート |
| 利用料金 | Essential:85,000円~/月 最低利用価格は年間払いでの価格です。 使用する機能によって料金プランが異なりますので、お気軽にお問い合せください。 貴社に最適なプランをご提案いたします。 |
■Trinka Cloud 1ユーザー|月払い 20ドル/年払い 80ドル ■Trinka API お問合せください ※日本法人とのご契約、日本円でお支払いいただくことが可能です。 |
要件によって異なりますのでお問い合わせください | お問合せください |
| 初期費用 | 100,000円 | ■Trinka Cloud 無料(カスタマイズが必要な場合は別途ご相談) ■Trinka API お問合せください |
要件によって異なりますのでお問い合わせください | お問合せください |
| 無料プラン | お問合わせください | |||
| 無料 トライアル |
お問合わせください | お問合わせください | ||
| 製品リンク |
「EmmaTools」の 詳細はこちら |
「AI搭載・自動英文校正ツールTrinka」の 詳細はこちら |
「AI suite(エーアイスイート)」の 詳細はこちら |
「SpectA KY-Tool」の 詳細はこちら |
| 機能名・用語 | 解説 |
|---|---|
| あいまい検索 | ドキュメントから、入力された質問文と似通っているものを検索していく技術のことを指します。検索文の分解を行い、「出現頻度」「出現集中度」「出現位置」などを考慮した上でスコア化されます。 |
| 意図理解 | マルチモーダル自然言語理解技術により、会話音声から顧客の意図を汲み取ることができるとされる機能です。IVRでの入力作業も削減可能になります。 |
| 機械可読辞書 | 「コンピューターが単語の総体である語彙(ごい)を理解するために必要となる辞書」のことです。書き言葉の書籍情報や関連情報などを機械が正しく読み込むことができるように置き換えた通信規格です。 |
| 議事録自動作成AI | 会議の音声を自動で文字起こし(テキスト化)してくれるツールのことです。AI(人工知能)が搭載されているため、音声認識機能を活用し、高い精度で人が話す言葉を文字列に変換させることができます。 |
| コーパス | 自然言語処理を行う際に必要となる「自然言語の文章を構造化して大規模に集積したもの」を指します。このコーパスの分析を行うことで、状況に適した言葉の意味、使い方を理解することができます。 |
| セマンティック検索 | 利用者が入力した検索文の意味に合ったデータを優先して、検索上位に表示します。検索文と検索対象の双方に、同社が独自に開発したAIによる構文解析と意味解析を行います。 |
| 全文検索 | 複数の文書から特定の文章が含まれているものを検索することです。パソコンに格納されているファイル(文書)の中から、特定のキーワード文章が含まれているファイルを検索することも指します。 |
| 対話型AI | NLP(自然言語処理) 技術を駆使することで、人間のような会話を自然に行うことができるため、リアルタイムでの顧客支援が可能です。 |
| 逐次検索 | ユーザーが文字を入力するたびに検索を実行します。 全体を入力する前に検索を開始し、一文字進むごとに検索結果が更新されるのが特徴です。 |
| BERT | Bidirectional Encoder Representations from Transformersを略した自然言語処理モデルであり、2018年10月にGoogle社のJacob Devlin氏らが発表した。特徴として、「文脈を読めるようになったこと」が挙げられます。 |
| NLP(自然言語処理) | 私たちが使用している言葉(自然言語)をコンピューターによって処理させる技術のことを指します。なお、自然言語と対比する言葉として挙げられるのが人工言語です。 |
プロダクト資料をまとめて
比較・確認したい方はこちら
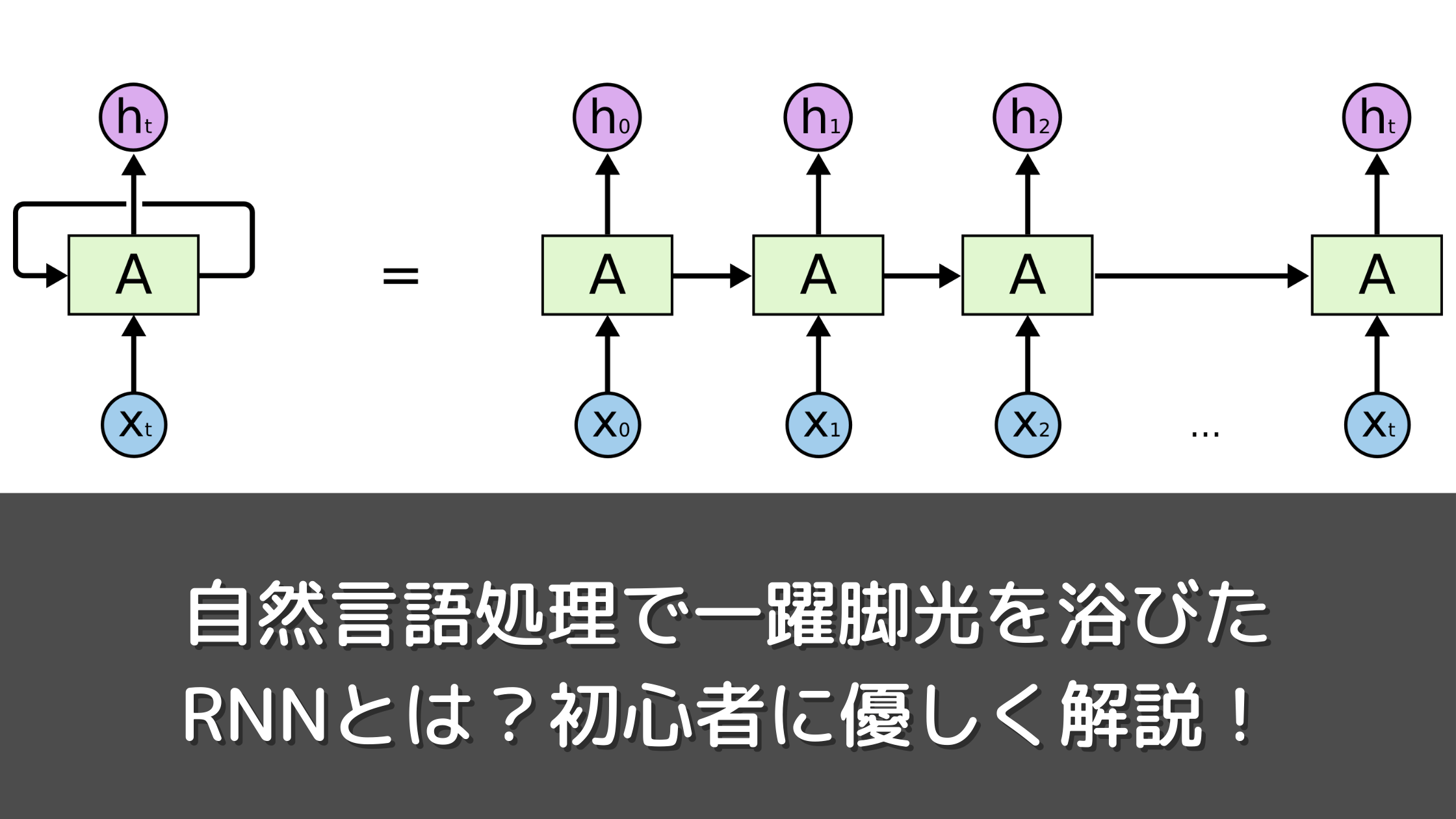
自然言語処理とは、人間が使用している言葉である「自然言語」をコンピュータ上で処理する技術のことです。自然言語はこれまでコンピューター上での処理が難しいとされてきました。しかし機械学習の発展により、近年ではチャットボットや音声認識などさまざまな分野で活用されています。
そんな自然言語処理の歴史は古く、1940〜1960年頃に黎明期と呼ばれ、1946年に初めてコンピュータが誕生しました。1990年頃から現在までは「発展期」と呼ばれており、2010年代に入ると、画像認識や音声認識といったさまざまなタスクにおいて、大幅な精度の向上が見受けられるようになりました。
ここからは、自然言語処理の導入を検討されている方に向けて、導入前の注意点をご紹介します。
自然言語処理の導入にあたり重要なことは、自社で「解決したい課題」や「目的」を明確にすることです。たとえば、以下のような課題・目的が考えられます。
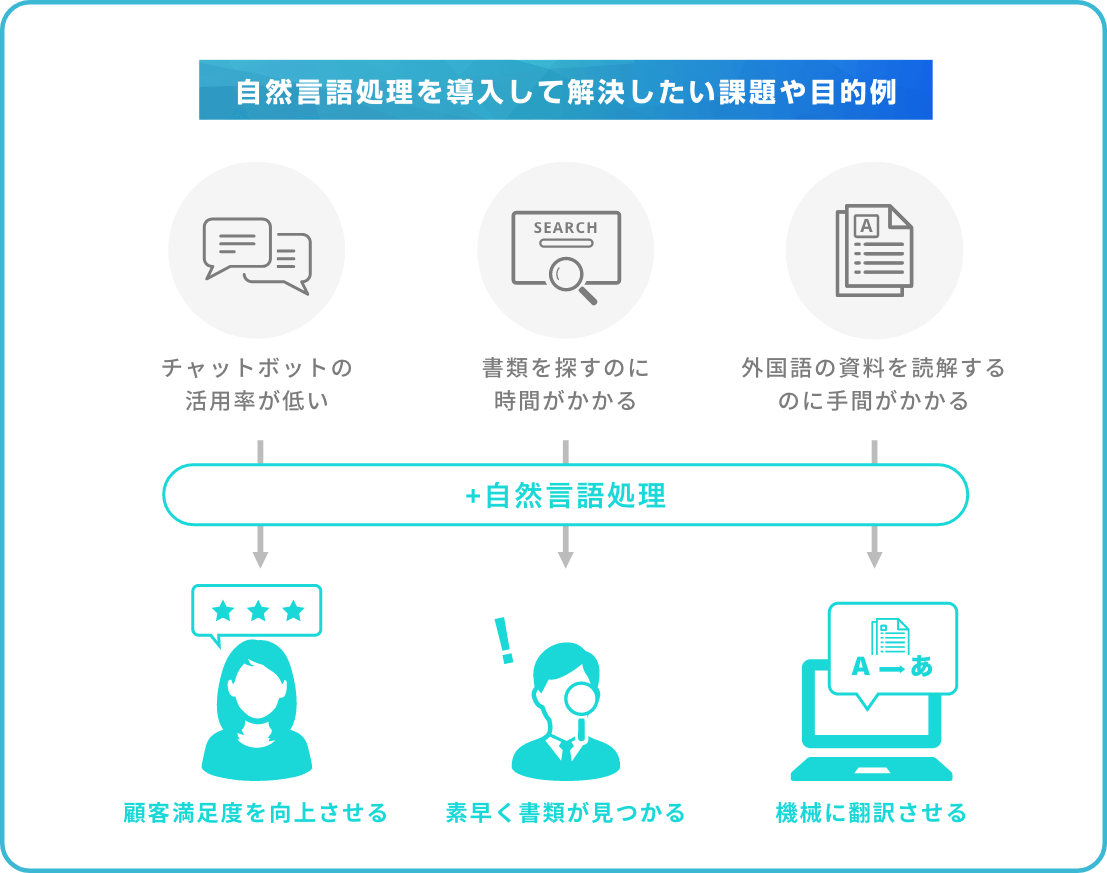
以上のように目的と課題をできるだけ具体的にしておくと、プロダクトやサービスの検討が進めやすくなります。
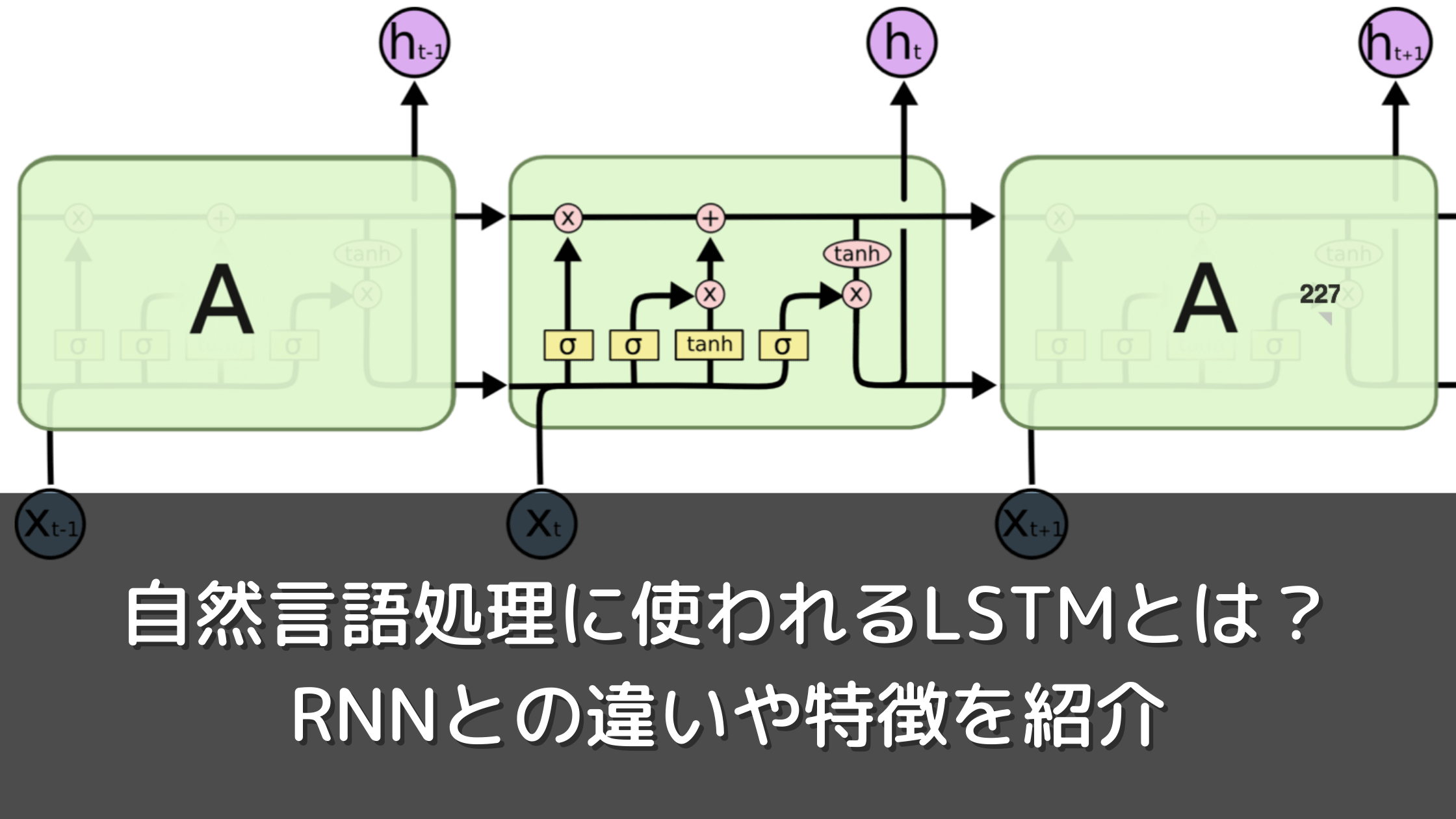
自然言語は、プログラミング言語とは異なり曖昧性が存在するわけですが、その曖昧性を克服し、適切な形でテキストデータを活用するために用いられるのが「自然言語処理」という技術です。そんな自然言語処理を行うためには、「機械可読辞書」と「コーパス」の2つが欠かせません。
機械可読辞書とは、「コンピューターが単語の総体である語彙(ごい)を理解するために必要となる辞書」のことです。書き言葉の書籍情報や関連情報などを機械が正しく読み込むことができるように置き換えた通信規格であり、いわば「ロボットの目」のような役割を担っています。
コーパスとは、自然言語処理を行う際に必要となる「自然言語の文章を構造化して大規模に集積したもの」を指します。このコーパスの分析を行うことで、状況に適した言葉の意味、使い方を理解することができるようになるわけです。最近では、コンピューター自体の処理性能や記憶容量も高まってきている状況にあるため、より大規模なコーパスを利用して言語処理を行うことができるようになっています。
機械可読辞書とコーパスの用意が完了すると、次に行われるのが形態素解析という作業です。「形態素」は言語学の用語であり、意味を持つ表現要素の最小単位のことです。これだけでは意味が分からない方も多いかと思いますので、先ほどの「黒い目の大きい金魚」という言葉を用いて解説していきます。
この「黒い目の大きい金魚」というフレーズは、「黒い」「目」「の」「大きい」「金魚」という形態素で分割することができるわけです。このように分割していく作業を「形態素解析」と呼びます。
構文解析とは、「一つひとつの形態素データがどの形態素データと隣り合わせになっているのか」を確認していく工程のことです。日本語の構文解析では、形態素解析によって分割された単語同士の関連性を解析した上で、「分節感の係り受け構造を見つけてツリー化(図式化)していくこと」が主な目的となっています。そんな構文解析には、以下2つの解析手法が存在します。
依存構造とは、単語や文節間における「修飾・被修飾関係」「係り受け関係」などの依存関係をもとに、文章の構造を表したものです。単語・文節を接点とするツリーによって表現されます。つまり依存構造解析は、文章内における「単語間の係り受け関係」を調べた上で、「どの単語がどの単語に係るのか」を構文的に解析していく作業というわけです。
意味解析とは、構文解析された文章内の意味を解釈していく工程のことです。日本語の場合、ひとつの原文に対して複数の解釈ができるケースも少なくありません。その一例として、以下のような文章が挙げられるでしょう。
「私は冷たいビールとメロンが好きだ。」
この文章の場合、「私は|冷たい|ビールとメロン|が好きだ。」という解釈であればどちらも「冷たい」と認識できます。しかし、「私は|冷たいビール|と|メロン|が好きだ。」という解釈であれば、メロンの冷たさは問わないことになるわけです。
このように、複数の解釈ができる文章において、正しい解釈を選択するために必要となるのが意味解析です。
文脈解析とは、文章の繋がり(文脈)を考えていく工程のことです。複数の文に対して「文同士のつながり」を解析するためには、文章の背景など複雑な情報も必要になります。
そのため、意味解析よりもさらに難易度は高く、現状では実用分野への応用が難しいといわれています。
では、自然言語処理を導入した場合、どのようなメリットが得られるのでしょうか。また、どのようなデメリットが生じる可能性があるのでしょうか。メリット・デメリットを詳しくみていきましょう。
自然言語処理を導入するメリットとして挙げられるのは、SNSの普及に伴いチャットツールの需要が高まっていることが挙げられるでしょう。今後さらにチャットツールの利用は増加していくことが予想されており、テキストデータ量は増加していくため、もはやテキストデータの活用は必要不可欠と言っても過言ではありません。
そのような中で自然言語処理を有効活用できれば、さらなる業務効率化を実現したり、多くの企業が課題としている人材不足を解消したりと、さまざまなメリットを得ることができます。
自然言語処理のデメリットとして挙げられるのは、必ずしも言語を正しく処理できるとは限らないという点です。特に、感情を正しく認識するのは難しい傾向にあり、発言と感情が一致せずにニュアンスが伝わりにくくなってしまうというケースは多く見受けられます。
そのため、テキストから感情認識した場合と、音声から感情認識した場合で結果が異なってしまうことがある点は、自然言語処理の課題(デメリット)の一つといえるでしょう。とはいえ、自然言語処理の分野は日々進歩しているため、今後これらの課題が解消されていく課題も十分にあります。そのため、今後期待されるポイントとして捉えることもできるでしょう。
「自社の課題が、自然言語処理導入によって解決されるのか分からない」という方に向けて、自然言語処理を活用されている分野をご紹介します。
「検索システム」はGoogle検索などさまざまな場面で使用されています。それらの検索システムの中でも、キーワードごとに区切らなくても自然言語で検索できるシステムには、自然言語処理が用いられています。
精度の高い「検索システム」は、目的のデータと完全に一致しない言葉で検索した場合でも、言語から正しく意味を解釈し目的の検索結果を探し当てることができます。
「チャットボット」は自然言語処理が用いられている代表的なサービスの1つです。ユーザーが入力した文に対して、文脈や意味を読み取り最適な回答を導き出します。
特に日本語では文中で主語が省略されがちですが、自然言語処理を導入したチャットボットであれば直前の会話に出てきた主語を記録し意味をくみ取ることも可能です。
「音声認識」は、認識された音声をテキスト化する際に自然言語処理を用いています。この技術は、議事録の作成によく用いられています。自然言語処理搭載の音声認識AIを使用すれば、会議が終了するタイミングで議事録は概ね完成します。
手書きの文書や帳票を読み取って電子化する技術である「AI-OCR(文字認識)」にも、自然言語処理が活用されています。手書き文字の認識において、自然言語処理を用いるとAI自身が文字の特徴抽出やモデル学習を行えます。
SiriやAlexaのようなスマートスピーカーに用いられている対話システムも、自然言語処理によって実現しています。自然言語で話しかけた場合でも的確に意図を解釈し指示に従うことができます。
テキストマイニングは、膨大なテキストデータから目的の情報を探し出す際に用いられます。自然言語処理は、テキストマイニングでビッグデータからデータを分析する段階で、テキストを適切な構造データに変換する際に用いられます。

文章を名詞・形容詞・動詞などの単語に分割し、単語同士の相関関係や出現頻度を分析することで有益な情報を判断し抽出します。
前述した事例以外にも、自然言語処理が活用されている事例はたくさんあります。導入を検討されている場合は、一度開発会社やサービス提供会社に相談してみることをおすすめします。
※ビッグデータ・・・従来のシステムでは管理、分析が難しいような巨大なデータ群
自社の目的に合う最適な自然言語処理製品を選ぶためのコツをご紹介します。
自然言語処理は幅広い分野で活用されているため、まずは自社の課題・目的が属する「分野」を明確にすることをおすすめします。
例)検索システムの開発が必要な場合
検索システム開発の実績やノウハウを保有している会社に相談することで業務設計が円滑に進むことが期待できます。
自然言語処理は製品やサービスによって動作環境が異なりますので、自社で使用予定の環境が対象に含まれるか確認をしておくことが重要です。
例)チャットボットを導入する場合
LINEやMicrosoft Teams/365に対応しているかなどが確認のポイントになるでしょう。

また、複数の言語に自然言語処理を活用したい場合は対応言語を確認することも欠かせません。
製品を導入する際にかかるコストや、対応環境、対応言語の使いやすさなどを検討することも非常に大切です。魅力的な機能が多く搭載されている製品であっても、その製品の導入・運用コストが自社の予算を大幅に上回ってしまっては意味がありません。そのため、自社の予算を明確化した上で、その予算に見合う最適な製品を検討していくと良いでしょう。
また、最近では無料で使用感を試すことができる製品も存在するため、それらをお試しで活用してみるのも一つの手段といえるでしょう。
データ量や出力の精度を確認しておくことも、非常に重要なポイントの一つです。製品ごとに出力の精度は異なるため、より高い精度を実現できる製品を見極めなければなりません。最近では、無料トライアルが設けられている製品も存在するため、トライアルを活用して自社との相性をチェックしていくのも効果的な手段といえるでしょう。
数ある「自然言語処理」の中から、自社の課題や導入の目的にあった「自然言語処理」を選び出すのは容易ではありません。そんな時に役立つのが、用途別にセグメントされた自然言語処理カオスマップです。

この便利なカオスマップとサービスベンダー一覧は、以下の「カオスマップと自然言語処理サービスベンダー一覧を無料でダウンロードする」ボタンより無料でダウンロードできます。
自然言語処理の精度は日々向上していますが、下記の様に処理が困難な場合もあります。円滑な運用を行うために、自動言語処理で注意が必要な点を押さえておきましょう。
自然言語処理の文脈解析は、まだ精度が十分な実用性に達していません。「それはやばいですね」などのように文脈によって解釈が異なる言語には注意が必要です。
自然言語処理は人間と異なり一般常識を持っていません。そのため、「毎日空を飛んで出勤する」という文章に対して人間は「おかしい」と判断できますが、自然言語処理では簡単に判断することはできません。
言語によって文章の体系は大きく異なります。そのため、自然言語処理がその違いにどう対処していくかというのは課題の1つです。システムのアルゴリズムが、対象言語に大きく依存しないよう対処する難易度は非常に高いと言えます。

以上のような自然言語処理の難易度が高い点に関しては、重点的に学習をさせチューニングを行うことで対策すると良いでしょう。
無料
全サービス資料請求


目的から探す
業務の課題解決に繋がる最新DX・AI関連情報をお届けいたします。
メールマガジンの配信をご希望の方は、下記フォームよりご登録ください。登録無料です。
実際のメールマガジン内容はこちらをご覧ください。